Minicontest: Dreh den Satz.
Übersicht


|
BladeRunnerModeratorBetreff: Minicontest: Dreh den Satz. |
Antworten mit Zitat |
|---|---|---|
|
Hi,
ich bin beim stöbern in einem anderen Forum auf eine lustige kleine Aufgabe gestoßen die ich hier auch stellen möchte: Schreibt ein Programm welches alle Wörter (um genau zu sein: nur die Buchstaben!) eines Satzes umdreht und den Satz dann ausgibt. Ein Beispiel: "Dies ist der 1. Testsatz!!einself!" wird zu: "seiD tsi red 1. ztastseT!!flesnie!" Das Programm darf in jeder beliebigen Sprache verfasst werden und muss mit allen Buchstaben des englischen Alphabetes funktionieren. Wer das kürzeste (fehlerfreie!) Programm in Byte abgibt gewinnt! Deadline: 31.12.13 23.59 Damit das warten auf Silvester ein wenig leichter wird Viel Erfolg! |
||
|
Zu Diensten, Bürger.
Intel T2300, 2.5GB DDR 533, Mobility Radeon X1600 Win XP Home SP3 Intel T8400, 4GB DDR3, Nvidia GF9700M GTS Win 7/64 B3D BMax MaxGUI Stolzer Gewinner des BAC#48, #52 & #92 |
||

|
Addi |
Antworten mit Zitat |
|---|---|---|
|
Mein Prog:
https://dl.dropboxusercontent....Invert.bmx Edit: noch nicht ganz regelkonform *ups* |
||
| BP/B3D/BMax : Lerne Java : Früher mal Lite-C : Gewinner BCC 62 | ||
|
|
SpionAtomBetreff: Abgabe |
Antworten mit Zitat |
|---|---|---|
|
https://dl.dropboxusercontent....densatz.bb
https://dl.dropboxusercontent....ortcode.bb (253 Byte) Der zweite Code ist leicht anders. |
||
| os: Windows 10 Home cpu: Intel Core i7 6700K 4.00Ghz gpu: NVIDIA GeForce GTX 1080 | ||

|
d-bug |
Antworten mit Zitat |
|---|---|---|
BlitzMax: [AUSKLAPPEN] Local s$=Input(">")+" ",r$,p%;For i=0 Until s.length;If Not((s[i]>=65 And s[i]<=90)Or(s[i]>=97 And s[i]<=122)) Diese Variante hat 226Byte und ist BlitzMax! (ist ja kaum noch zu erkennen, bei dem gekürztem Shit da) Ich erhebe keinerlei Anspruch auf eine 100%ige Funktionalität aber sie funktioniert zumindest mit deinem Testsatz einwandfrei. Ist auf jeden Fall ein niedlicher Contest. Hatte gerade echt Lust das mal zu testen. Update: Jetzt sinds 208Byte, dafür ist auch ein kleiner Bug behoben, der das String-Ende falsch auswertete. |
||
- Zuletzt bearbeitet von d-bug am Fr, Dez 27, 2013 2:22, insgesamt einmal bearbeitet
|
|
D2006Administrator |
Antworten mit Zitat |
|---|---|---|
|
Zwar sind alle Sprachen erlaubt, aber dennoch laufe ich gerne außerhalb der Konkurrenz. Ich nutz hier eine Sprache, die quasi für solche Aufgaben geschaffen wurde. Deshalb ist das ein wenig Schummelei. Aber vielleicht ist es für den ein oder anderen ja was erkenntnisreiches, deswegen poste ich das mal:
Code: [AUSKLAPPEN] sub w(){$_[0]=~s/(\w+)/reverse $1/eg;$_[0];}
Dies ist eine 44-Byte lange Perl-Funktion, die das macht. Da ich nicht genau weiß, wie gezählt wird, hier ein Testprogramm, welches den Satz aus den Übergabeparametern ausliest: Code: [AUSKLAPPEN] #!/usr/bin/perl
print w($ARGV[0])."\n"; sub w(){$_[0]=~s/(\w+)/reverse $1/eg;$_[0];} Das wären dann 86 Bytes. Beweisbild der Funktionalität Jetzt noch für den pädagogischen Wert eine kleine Erklärung der Funktionsweise: Code: [AUSKLAPPEN] sub w() {
$_[0] =~ s/(\w+)/reverse $1/eg; $_[0]; } "sub w()" deklariert die Funktion. $_[0] ist der Zugriff auf den ersten Parameter der Funktion (alle Parameter landen in Perl quasi im @_-Array). "=~" bedeutet, dass ich den String ($_[0]) gerne via Regulären Ausdruck bearbeiten möchte. Das erste "s" gibt an, dass ich suchen & ersetzen möchte. Die "/" dienen als Delimiter der Parameter des RegEx-Ausdrucks (könnte z.B. auch § nehmen, solang es das erste Zeichen nach "s" ist). Zwischen dem ersten und zweiten "/" steht der Reguläre Ausdruck, den ich finden möchte. In diesem Fall alle Buchstaben die ein Wort bilden ("\w"), wobei dieses Wort mindestens ein Zeichen haben soll (+) und die Klammern sorgen dafür, dass ich darauf zugreifen kann. Ganz hinten steht ein "e". Das steht für "eval" und bedeutet, dass die Ersetzung evaluiert werden soll. Zwischen dem zweiten und dritten "/" steht quasi ein Ausruck, der ausgeführt wird. Dessen Rückgabewert ist der String, mit dem ich den Fund ersetzen möchte. "$1" greift dabei auf das zuvor gefundene, mindestens ein Zeichen lange Wort zurück. "reverse" ist eine Standardfunktion von Perl, die Arrays oder Strings (je nach Kontext) umdreht und zurückgibt. Das "g" am Ende steht für "global" und bedeutet, dass die Ersetzung so oft wie möglich durchgeführt werden soll (ansonsten wird nur das erste Wort ersetzt). Die letzte Zeile ist ein kleiner Trick: eine Perl-Methode gibt immer den zuletzt gesetzten Wert zurück. Wenn ich also einfach "$foo" schreibe, wird "return $foo;" ausgeführt, aber ich kann ein paar Bytes sparen. |
||
|
Intel Core i5 2500 | 16 GB DDR3 RAM dualchannel | ATI Radeon HD6870 (1024 MB RAM) | Windows 7 Home Premium
Intel Core 2 Duo 2.4 GHz | 2 GB DDR3 RAM dualchannel | Nvidia GeForce 9400M (256 MB shared RAM) | Mac OS X Snow Leopard Intel Pentium Dual-Core 2.4 GHz | 3 GB DDR2 RAM dualchannel | ATI Radeon HD3850 (1024 MB RAM) | Windows 7 Home Premium Chaos Interactive :: GoBang :: BB-Poker :: ChaosBreaker :: Hexagon :: ChaosRacer 2 |
||
|
|
ZEVS |
Antworten mit Zitat |
|---|---|---|
|
Gegen D2006 habe ich keine Chance, aber die ganzen imperativen Versuche sollten relativ leicht zu übertreffen sein. Das beste, was ich soweit erreicht habe, sind 128 Bytes in der funktionalen Programmiersprache Miranda: Code: [AUSKLAPPEN] l=letter
m=(~).l t=takewhile d=dropwhile h(a,b)=(a++(reverse(t l b))++(t m(d l b)),d m(d l b)) f x=fst(limit(iterate h ([],x))) Zur Erläuterung: l ist eine Abkürzung für letter, m für das Gegenteil hiervon (hierfür muss man eine eigene Funktion definieren), t für takewhile und d für dropwhile. h bekommt ein Tupel von zwei Strings und liefert auch ein solches zurück. Zu Beginn ist das linke Tupel leer und im rechten befindet sich der zu bearbeitende Satz. In jedem Schritt werden zunächst die am Satzanfang befindlichen Buchstaben umgekehrt an den ersten String angefügt und dann die hierauf folgenden nicht-Buchstaben. Aus dem zweiten String werden mit einem doppelten dropwhile die somit bearbeiteten Zeichen entfernt. Durch iterate kann man die Funktion beliebig oft auf sich selbst anwenden, mit limit wird dann das Ergebnis ermittelt und mit fst der Ergebnis-String ausgewählt. Dieses genau tut die Funktion f, welche die eigentliche Berechnungs-Funktion ist. Ein Beispiel-Aufruf: Code: [AUSKLAPPEN] Miranda f "Dies ist der 1. Testsatz!!einself!"
seiD tsi red 1. ztastseT!!flesnie! ZEVS edit: Habe eine Möglichkeit mit 125 Buchstaben gefunden: Code: [AUSKLAPPEN] l=letter
c=(#).takewhile l h s i=i-c(drop(#s-i)(reverse s))+c(drop i s)-1,if l(s!i) =i,if 1=1 f s=map(s!)(map(h s)(index s)) |
||

|
DAK |
Antworten mit Zitat |
|---|---|---|
|
Code: [AUSKLAPPEN] String o="",p[]=t.split("(?<=\\W)|(?=\\W)");for(String s:p){o+=new StringBuffer(s).reverse();}
94 Zeichen in Java. Dabei muss der Eingabestring in t sein und die Ausgabe landet in o. Zur Funktionsweise: t.split("(?<=\\W)|(?=\\W)") splittet den String entlang von allen nicht-alphanumerischen Zeichen wobei diese Delimiter-Zeichen erhalten bleiben. Die einzelnen Tokens werden dann in der For-Schleife durchlaufen, in StringBuffers geschrieben, die dann umgedreht werden und wieder an den String angehängt werden. Man sollte in neueren Java-Versionen eher StringBuilders verwenden statt StringBuffers, da diese performanter sind, allerdings haben diese einen Buchstaben mehr im Namen, weswegen ich es gelassen habe. Mit der Apache Commons Library kann man den StringBuilder-Teil auch durch StringUtils.reverse(s); ersetzen, was die Länge um 7 Zeichen auf 87 Zeichen drücken würde. @Kürzestes Programm in Byte: Ich nehme an, dass du da simplifizierst und meinst, das kürzeste Programm in Bytes kodiert in ASCII, oder? Wenn da z.B. UTF-16 verwendet wird, ist jedes Zeichen zwei Byte lang, und bei UTF-8 können es auch 5 Bytes pro Zeichen werden. Genauere Definition wäre wohl Zeichen, oder? @Zevs: Hab dich hier mit einer imperativen Sprache ein gutes Stück weniger Zeichen als du. |
||
| Gewinner der 6. und der 68. BlitzCodeCompo | ||
|
Lakorta |
Antworten mit Zitat |
|---|---|---|
|
@DAK
Ich würde sagen, Bladerunner meint mit den Bytes die größe der ausführbaren Datei des Programmes, nicht die größe des Quellcodes, oder? |
||
| --- | ||

|
RallimenSieger des 30-EUR-Wettbewerbs |
Antworten mit Zitat |
|---|---|---|
|
Hallo, ich habs auch mal probiert in BlitzBasic
Code: [AUSKLAPPEN] A$=""
;----------------121 Byte For i=1To Len(a)C$=Mid(A,i,1)d=Asc(C) If d>64And d<91Or d>96And d<123 B$=C+B Else S$=S+B+C b="" EndIf Next S=S+b ;---------------- Print S WaitKey der gekürzte Functions-Code ohne ein/Ausgabe ist 121 Byte lang Als ausführbare Datei liegt BB3D bei über 1MB mit Ein/ausgabe natürlich mehr! |
||
|
[BB2D | BB3D | BB+]
|
||
|
|
DAK |
Antworten mit Zitat |
|---|---|---|
|
Lakorta hat Folgendes geschrieben: @DAK
Ich würde sagen, Bladerunner meint mit den Bytes die größe der ausführbaren Datei des Programmes, nicht die größe des Quellcodes, oder? Das kann ich mir kaum vorstellen, das würde dann nämlich heißen, dass es rein auf die Sprache ankommt, die man verwendet. Kompiliert man eine leere Datei in BB, dann kriegt man schon über 1 MB raus. Kompiliert man die Zeile "Framework BRL.StandardIO" in BlitzMax dann hat man ~100 KB und wenn man eine Skriptsprache verwendet wie Ruby oder PHP, dann wird die gar nicht kompiliert, die ausführbare Datei wäre dann im Grunde die Textdatei, was dann <1 KB wäre. Da heißt es dann nicht, wer kann am besten programmieren sondern einzig, wer findet die Sprache, die die kleinsten Dateien macht. |
||
| Gewinner der 6. und der 68. BlitzCodeCompo | ||
|
|
ZEVS |
Antworten mit Zitat |
|---|---|---|
|
Das wäre m.M.n. der erste Wettbewerb, wo es um die Größe von auführbaren Dateien ging. Zudem ist dieses bei Skriptsprachen nicht hilfreich (na, wer legt mir eine Exe mit < 125 Bytes vor?).
Ich würde mir hierum beim Veranstalter des Wettbewerbs Klärung erhoffen. Außerdem wäre ein Feedback, was ganau zu den Bytes zählt und was nicht, hilfreich (s. Beitrag von Rallimen). edit: BRs Meinung zur Verwendung von RegExps interessiert mich auch. @DAK: Wenn ich folgendes Programm kompilliere und ausführe: Code: [AUSKLAPPEN] public class temp {
public static void main (String[] arg) { System.out.println(Reverser(arg[0])); } public static String Reverser(String t) { String o="",p[]=t.split("(?<=\\W)|(?=\\W)");for(String s:p){o+=new StringBuffer(s).reverse();} return o; } } erhalte ich folgendes Ergebnis: Code: [AUSKLAPPEN] >javac temp.java
>java temp "Hallo Welt 123" ollaH tleW 321 Die erwartete Ausgabe nach meiner Kenntnis der Regeln wäre dagegen "ollaH tleW 123". ZEVS |
||
- Zuletzt bearbeitet von ZEVS am Sa, Dez 28, 2013 15:32, insgesamt einmal bearbeitet
|
|
DAK |
Antworten mit Zitat |
|---|---|---|
|
Oh, sorry, hab überlesen, dass Zahlen nicht gedreht werden sollen.
Korrigiert schaut das dann so aus: Code: [AUSKLAPPEN] String o="",p[]=t.split("(?<=[^a-zA-Z])|(?=[^a-zA-Z])");for(String s:p){o+=new StringBuffer(s).reverse();}
Das bläst den Code auf 106 Zeichen auf. Die kürzere Variante mit der Apache Commons Library kommt jetzt auf 99 Zeichen: Code: [AUSKLAPPEN] String o="",p[]=t.split("(?<=[^a-zA-Z])|(?=[^a-zA-Z])");for(String s:p){o+=StringUtils.reverse(s);}
|
||
| Gewinner der 6. und der 68. BlitzCodeCompo | ||
feiderehemals "Decelion" |
Antworten mit Zitat |
|
|---|---|---|
|
Und mein kleiner Beitrag:
Code: [AUSKLAPPEN] #include <iostream>
using namespace std;int main(){char c;while(1){string w;cin.get(c);while((c>='a'&c<='z')|(c>='A'&c<='Z')){w=c+w;cin.get(c);}cout<<w<<c;}} 168 Bytes, bzw Zeichen - schade EDIT: 166 Bytes - Hatte da doch glatt noch unnötige Leerzeichen drin Hier der Code nochmal schön formatiert: Code: [AUSKLAPPEN] #include <iostream>
using namespace std; int main() { char c; while(1) { string w; cin.get(c); while((c>='a'&c<='z')|(c>='A'&c<='Z')) { w=c+w; cin.get(c); } cout<<w<<c; } } Doppeledit: Ging noch kurzer. 157 Zeichen, Code ist angepasst. |
||
TheKilledDeath |
Antworten mit Zitat |
|
|---|---|---|
|
Zwar nicht ganz so kurz wie die Perl Variante, aber hier meine in Python:
Code: [AUSKLAPPEN] import re
for x in re.findall("[a-zA-Z]+",s): s=s.replace(x,x[::-1]); 70 Bytes, Eingabestring muss in s liegen, Ausgabestring liegt wieder in s. (Zwischenedit: Wenn man imports weglassen darf, was ja hier einige getan haben, kommt es natürlich auf 60 Bytes) Beispiel mit dem ganzen unwichtigen Zeug aussen rum (132 Bytes): Code: [AUSKLAPPEN] import re
-> seiD tsi red 1. ztastseT!!flesnie!
def i(s): for x in re.findall("[a-zA-Z]+",s): s=s.replace(x,x[::-1]); print s i("Dies ist der 1. Testsatz!!einself!") Zur Erklärung: re.findall wendet ein regex auf den String an und gibt alle Ergebnisse in eine Liste. Über diese Liste wird mittels x iteriert, danach werden alle Vorkommen von x im String durch x[::-1] ersetzt, was einer invertierten Ausgabe des Wortes entspricht. |
||
|
|
BladeRunnerModerator |
Antworten mit Zitat |
|---|---|---|
|
Also:
- Es zählt die Größe in Byte der Quelldatei, wobei ich natürlich von einem Byte pro Zeichen ausgehe - hier werden ja keine abstrusen Sonderzeichen benötigt. - Importe dürfen nur weggelassen werden wenn das Programm ohne sie problemfrei läuft. Beispiel: BMax - alles in der Standardinstallation wird ohne expliziten Import erkannt, Usermodule hingegen müssen explizit eingebunden werden. - Der Eingabestring wird nicht zur Dateigröße gezählt, da es ja je nach Sprache die verschiedensten Wege geben mag wie der denn so vorliegt. Allerdings müsste ich für einen Input-Befehl die Bytes schon rechnen. Ausschlaggebend ist, dass das Programm die BUCHSTABEN und NUR DIE BUCHSTABEN umdreht. Von mir aus kan Groß-/Kleinschreibung beim drehen ignoriert werden wenn es hilft, aber erkannt werden sollte beides, wenn die benutzte Sprache / das benutzte System es zulässt. Ansonsten bin ich begeistert mit welcher Vielfalt hier gearbeitet wird. |
||
|
Zu Diensten, Bürger.
Intel T2300, 2.5GB DDR 533, Mobility Radeon X1600 Win XP Home SP3 Intel T8400, 4GB DDR3, Nvidia GF9700M GTS Win 7/64 B3D BMax MaxGUI Stolzer Gewinner des BAC#48, #52 & #92 |
||
TheKilledDeath |
Antworten mit Zitat |
|
|---|---|---|
|
Okay, mit diesen Einschränkungen komme ich auf das folgende:
Code: [AUSKLAPPEN] import re
s="[INPUT STRING]" for x in re.findall("[a-zA-Z]+", s): s=s.replace(x, x[::-1]); Was auf 77 Bytes kommt, wenn man die Anführungsstriche beim s="" mitzählt, ohne sind es 75. Keine Ahnung ob die zum String zählen oder nicht |
||
|
|
RallimenSieger des 30-EUR-Wettbewerbs |
Antworten mit Zitat |
|---|---|---|
|
Habs mal mit input() geschrieben und Waitkey am Ende
Extrem gekürzt und bin bei 127 Byte Code: [AUSKLAPPEN] A$=Input()For i=1To Len(A)C$=Mid(A,i,1)d=Asc(C)If d>64And d<91Or d>96And d<123B$=C+B Else S$=S+B+C B=""
Next Print S+B WaitKey |
||
|
[BB2D | BB3D | BB+]
|
||
blitzatius |
Antworten mit Zitat |
|
|---|---|---|
|
PowerShell geht auch mit ins Rennen. Die Funktionsweise ist ähnlich wie bei DAK.
77 bytes als Funktion Code: [AUSKLAPPEN] function w($s){($s-split"(?<=\P{L})|(?=\P{L})"|%{$_[-1..-$_.length]})-join''}
61 bytes, mit der Annahme, dass der Text in $a vorliegt Code: [AUSKLAPPEN] ($a-split"(?<=\P{L})|(?=\P{L})"|%{$_[-1..-$_.length]})-join''
64 bytes, verarbeitet das erste Argument Code: [AUSKLAPPEN] ($args-split'(?<=\P{L})|(?=\P{L})'|%{$_[-1..-$_.length]})-join''
Update: Codes oben ersetzt. Screenshot zeigt alte Version. 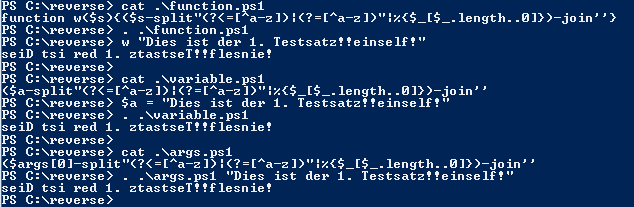
|
||
- Zuletzt bearbeitet von blitzatius am So, Dez 29, 2013 16:32, insgesamt 3-mal bearbeitet
|
|
DAK |
Antworten mit Zitat |
|---|---|---|
| Mit den Regeln ist Java leider draußen. Viel zu viel Overhead... (Das kommt davon, wenn man eine Sprache verwendet, wo lesbarer Code wichtiger ist, als ein paar Zeichen zu sparen...) | ||
| Gewinner der 6. und der 68. BlitzCodeCompo | ||

|
Thunder |
Antworten mit Zitat |
|---|---|---|
|
Also mein Quelltext ist wohl außer Konkurrenz.
Code: [AUSKLAPPEN] org 100h
mov di, string mov si, di mov ah, 1 read: int 21h cmp al, 13 je @f stosb jmp read @@: mov bx, di mov ah, 2 revloop: lodsb cmp al, 65 jb nonalpha cmp al, 122 ja nonalpha cmp al, 97 jae alpha cmp al, 90 jbe alpha nonalpha: .revloop2: cmp bx, di je @f dec di mov dl, [di] int 21h jmp .revloop2 @@: mov dl, [si-1] int 21h cmp si, bx je _exit jmp revloop alpha: stosb jmp revloop _exit: ret string: aber wenn man Maschinencode rechnet, bin ich bei 63 Byte! (Edit: Also noch 6 Byte gespart!) Und Assemblercode ist eigentlich nur eine andere Notation für Maschinencode Maschinen-Code: [AUSKLAPPEN] BF 3F 01 89 FE B4 01 CD 21 3C 0D 74 03 AA EB F7 89 FB B4 02 AC 3C 41 72 0C 3C 7A 77 08 3C 61 73 1A 3C 5A 76 16 39 FB 74 07 4F 8A 15 CD 21 EB F5 8A 54 FF CD 21 39 DE 74 05 EB D9 AA EB D6 C3
(In einem Hexeditor abspeichern mit Endung .COM) Auszuführen in einer DOSBox oder eventuell funktioniert es auch auf 32bit-Windows. 
Edit: Den Quelltext habe ich auch so gut es geht gestaucht, auf 298 Byte. Jede Hochsprache, in der die Lösung länger ist, sollte sich schämen kaum noch wiedererkennbarer Code: [AUSKLAPPEN] i equ int 33
c equ cmp al, m equ mov org 256 m di,e+1 m si,di m ah,1 r:i c 13 je f stosb jmp r f:m bx,di m ah,2 l:lodsb c 65 jb n c 122 ja n c 97 jae a c 90 jbe a n:cmp bx,di je g dec di m dl,[di] i jmp n g:m dl,[si-1] i cmp si,bx je e jmp l a:stosb jmp l e:ret |
||
- Zuletzt bearbeitet von Thunder am Do, Jan 02, 2014 14:26, insgesamt 2-mal bearbeitet
Übersicht
Powered by phpBB © 2001 - 2006, phpBB Group