Gesammelte Synapsenkurzschlüsse


2D Global Illumination
Da ich für ein aktuelles Sidescrolling-Projekt eine Lösung für Lightmaps in 2D-Levels suchte, experimentierte ich während der letzten Tage mit globaler Beleuchtung in 2D. Prinzipiell geht es darum, weiche Schatten und diffuse Beleuchtung zu berechnen, um das ganze ein wenig besser aussehen zu lassen.
Der Ansatz, den ich verwendete (namentlich Light Tracing) ist sehr simpel: Man sende Strahlen von einer Lichtquelle in zufällige Richtungen, lasse sie an Schnittpunkten mit dem Level in zufällige Richtungen weiterstreuen und, wenn der Strahl terminiert, markiere seine Strahlung auf der Lightmap. Lustigerweise ist das auswählen einer geeigneten zufälligen Richtung schwieriger als es klingt - je nach Oberfläche und Lichtquelle kommen ganz andere Wahrscheinlichkeitsverteilungen zum Einsatz, damit das Endresultat nicht verfälscht wird. Schlussendlich musste ich eine Art 3D-in-2D-Repräsentation zuhilfe nehmen, damit das Ganze funktioniert. Das macht zwar das generieren der Strahlen um einiges chaotischer, aber es scheint immerhin zu funktionieren
Das andere Problem war, effizient Schnittpunktberechnungen auszuführen. Da ich keine Einschränkungen auf die Form der Levels setzen wollte (z.B. nur gerade Linien sind erlaubt), verwendete ich einen Sparse Voxel Quadtree, der es erlaubt, mit beliebigen Pixellandschaften effizient Schnittpunkte zu finden. Lustigerweise ist er in der Testszene sogar um einiges schneller als die naive Implementation mit Linien-Linien-Schnittpunktberechnungen, obwohl der Code mit dem Quadtree um einiges komplexer ist.
Wie dem auch sei, hier ein Screenshot des Endresultats:

YT-Video:

Jetzt auch in HD!
Das Endresultat ist, obwohl relativ langsam, nicht ganz so schlecht herauskommen und wird vielleicht die eine oder andere Anwendung finden. Leider ist sie aber eher für Top-Down und Indoor-Spiele geeignet als für meinen Anwendungszweck, daher werde ich wohl etwas anderes suchen müssen.
Wer sich das ganze mal anschauen möchte, hier BMax Code und Exe für Windows: Download
Der Ansatz, den ich verwendete (namentlich Light Tracing) ist sehr simpel: Man sende Strahlen von einer Lichtquelle in zufällige Richtungen, lasse sie an Schnittpunkten mit dem Level in zufällige Richtungen weiterstreuen und, wenn der Strahl terminiert, markiere seine Strahlung auf der Lightmap. Lustigerweise ist das auswählen einer geeigneten zufälligen Richtung schwieriger als es klingt - je nach Oberfläche und Lichtquelle kommen ganz andere Wahrscheinlichkeitsverteilungen zum Einsatz, damit das Endresultat nicht verfälscht wird. Schlussendlich musste ich eine Art 3D-in-2D-Repräsentation zuhilfe nehmen, damit das Ganze funktioniert. Das macht zwar das generieren der Strahlen um einiges chaotischer, aber es scheint immerhin zu funktionieren
Das andere Problem war, effizient Schnittpunktberechnungen auszuführen. Da ich keine Einschränkungen auf die Form der Levels setzen wollte (z.B. nur gerade Linien sind erlaubt), verwendete ich einen Sparse Voxel Quadtree, der es erlaubt, mit beliebigen Pixellandschaften effizient Schnittpunkte zu finden. Lustigerweise ist er in der Testszene sogar um einiges schneller als die naive Implementation mit Linien-Linien-Schnittpunktberechnungen, obwohl der Code mit dem Quadtree um einiges komplexer ist.
Wie dem auch sei, hier ein Screenshot des Endresultats:
YT-Video:
Jetzt auch in HD!
Das Endresultat ist, obwohl relativ langsam, nicht ganz so schlecht herauskommen und wird vielleicht die eine oder andere Anwendung finden. Leider ist sie aber eher für Top-Down und Indoor-Spiele geeignet als für meinen Anwendungszweck, daher werde ich wohl etwas anderes suchen müssen.
Wer sich das ganze mal anschauen möchte, hier BMax Code und Exe für Windows: Download
Von Intros und Mandelkugeln
Aus Interesse setzte ich mich gestern mal dran, eine Implementation von Mandelbulbs zu schreiben. Eine erste Version, die das Fraktal zuerst in eine Volumentextur renderte und dann als Voxel geraytraced hatte, lief zwar relativ schnell, hatte aber eine relativ enttäuschende Qualität:
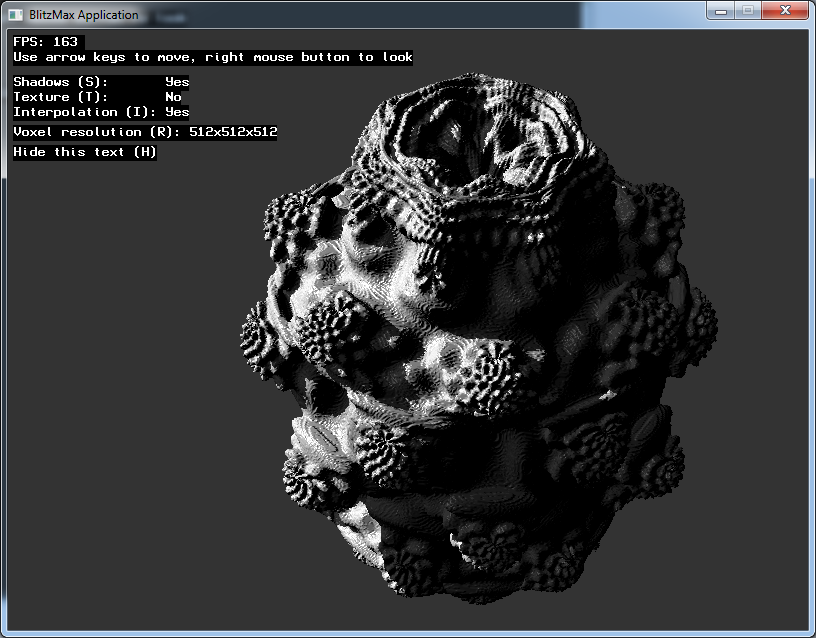
Eine zweite Version, bei der das Fraktal direkt in einem Shader geraymarched wird, sieht dann schon um einiges besser aus (Bilder anklicken für grössere Version):

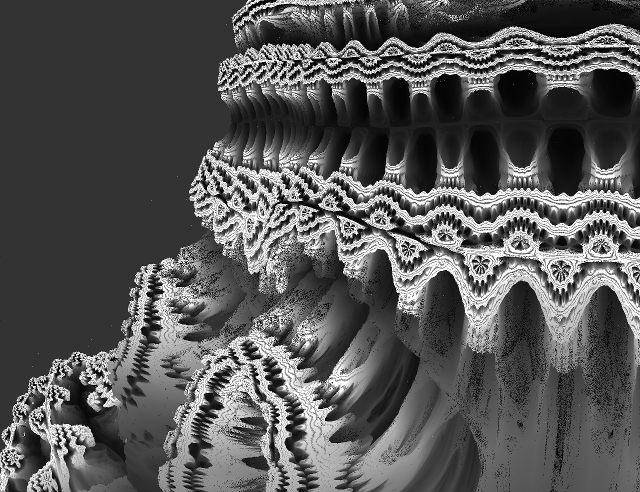
Dank Orbit Traps kann sogar ein gefaktes Ambient Occlusion berechnet werden, was nochmal einiges an Rechenzeit spart. Im Bild werden im Moment nämlich Beleuchtung und Schatten komplett ausgelassen, trotzdem aber sind alle Details erkennbar.
Ich habe im Moment noch ein wenig Probleme mit Bildrauschen, aber sobald ich das behoben habe, steht einer kleinen Demo nichts mehr im wege (obwohl man dafür wohl eine relativ starke Grafikkarte benötigt).
Ausserdem experimentiere ich grade ein wenig mit 4k Intros, bei denen es darum geht, grafische Effekte mit Musik in einer 4kb grossen Exe unterzubringen. Das ist zwar einiges schwieriger, als ich anfangs dachte, aber auch sehr spannend, daher werde ich mal versuchen, einige meiner älteren Programme in 4k unterzubringen.
Eine zweite Version, bei der das Fraktal direkt in einem Shader geraymarched wird, sieht dann schon um einiges besser aus (Bilder anklicken für grössere Version):

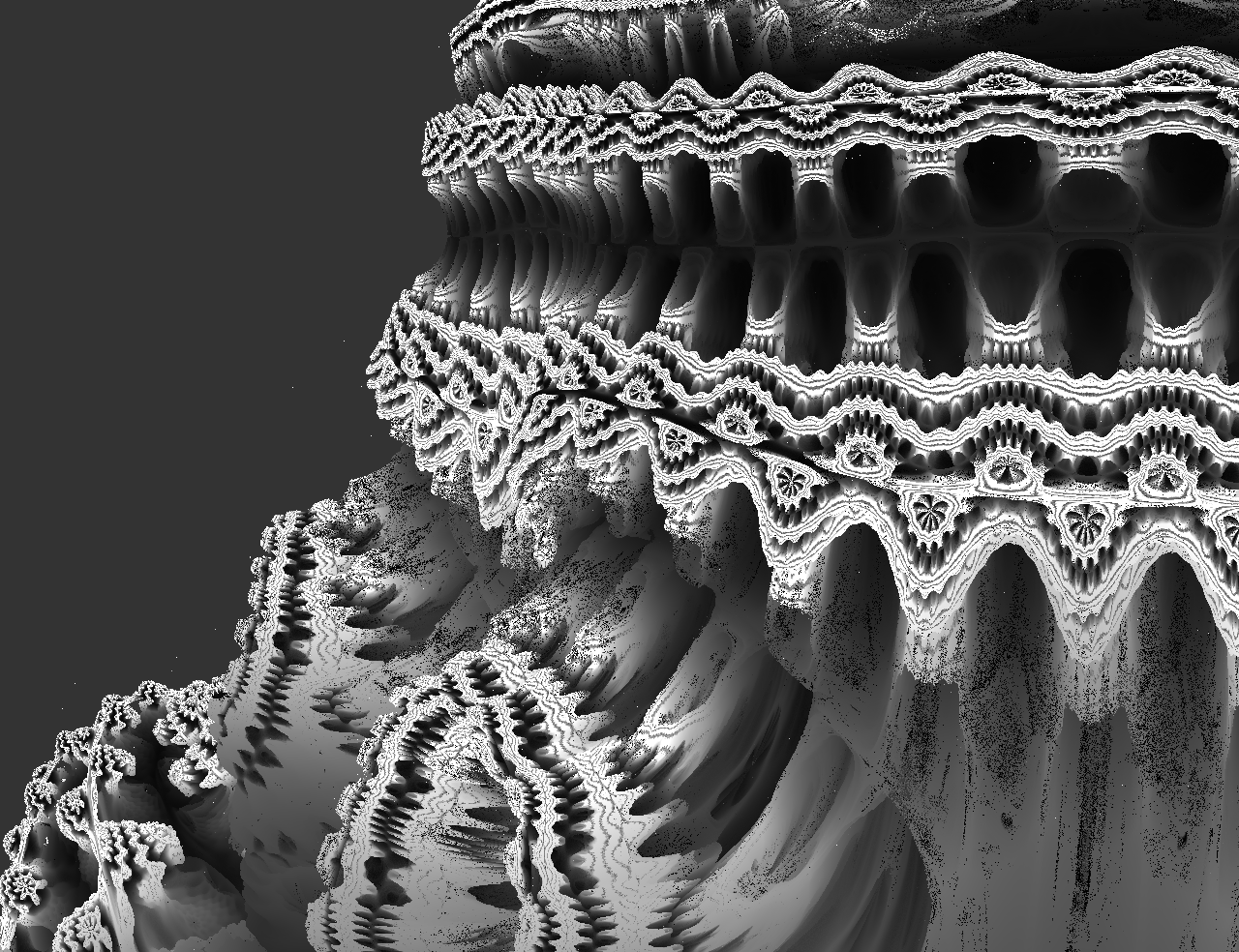
Dank Orbit Traps kann sogar ein gefaktes Ambient Occlusion berechnet werden, was nochmal einiges an Rechenzeit spart. Im Bild werden im Moment nämlich Beleuchtung und Schatten komplett ausgelassen, trotzdem aber sind alle Details erkennbar.
Ich habe im Moment noch ein wenig Probleme mit Bildrauschen, aber sobald ich das behoben habe, steht einer kleinen Demo nichts mehr im wege (obwohl man dafür wohl eine relativ starke Grafikkarte benötigt).
Ausserdem experimentiere ich grade ein wenig mit 4k Intros, bei denen es darum geht, grafische Effekte mit Musik in einer 4kb grossen Exe unterzubringen. Das ist zwar einiges schwieriger, als ich anfangs dachte, aber auch sehr spannend, daher werde ich mal versuchen, einige meiner älteren Programme in 4k unterzubringen.
Funktionsüberladung *britzel*
Nach ein wenig Umstrukturierung funktioniert nun auch die erste Version der Funktionsüberladung. Da der bestehende Ausdrucksparser ja sowieso schon den Datentyp eines Ausdrucks bestimmen muss, um Typenüberprüfung machen zu können, erwies sich das Schreiben das Algorithmus' zur Bestimmung der richtigen Variante der überladenen Funktion als relativ leicht.
Folgendes Beispiel BlitzMax: [AUSKLAPPEN]
Wie man sieht, wählt der Precompiler automatisch die richtige überladene Variante, wenn die Parametertypen exakt übereinstimmen.
Was aber, wenn die Typen nicht exakt übereinstimmen? BlitzMax: [AUSKLAPPEN]
Wichtig ist aber, dass Funktionen, die genau zutreffen, Vorrang haben vor Funktionen, die über Casting zutreffen würden BlitzMax: [AUSKLAPPEN]
Interessantes Verhalten lässt sich ausserdem feststellen, wenn man Funktionen und Methoden überlädt BlitzMax: [AUSKLAPPEN]
Verwirrend? Das ist es in der Tat. Aber aus Gründen der Sauberkeit sollte man sowas auch vermeiden.
Ein letztes Beispiel habe ich noch, das mit abgeleiteten Types funktioniert. Hier lassen sich wieder dieselben Verhaltensregeln beobachten BlitzMax: [AUSKLAPPEN]
Das Übersetzen ist dann weniger spektakulär. Funktionsnamen werden umgewandelt, indem an den Namen noch die Parametertypen in Kurzform angehängt werden. Der Aufruf wird auch umgewandelt, wobei das Programm per Backtracking bestimmt, von wo der Funktionszeiger herkommt. So könnte man auch den Funktionsnamen ausklammern und so Zeug, wie folgendes Beispiel unter anderem auch zeigt BlitzMax: [AUSKLAPPEN]
Das wird dann übersetzt in den folgenden Code BlitzMax: [AUSKLAPPEN]
Man beachte, dass der Rückgabetyp nicht im Funktionsnamen steckt und daher Funktionen mit gleichen Parametertypen, aber unterschiedlichen Rückgabetypen nicht erlaubt sind. Zu bestimmen, welcher Rückgabetyp erwartet wird, ist relativ schwierig umzusetzen.
Bis anhin kann man nur Funktionen und Methoden in Types überladen, dass muss ich noch mit einem kleinen Fix auch für normale Funktionen erlauben. Ausserdem funktioniert die Überladung noch nicht, wenn ein abgeleiteter Type die Methoden seiner Basisklasse überlädt - da muss noch was getan werden.
Ein neues Feature ist mir eingefallen, das ich wohl auch implementieren werde - Properties. Im Prinzip geht es darum, dass man für irgendein Field (z.B. Bar) die passenden Getter und Setter schreibt (hier also getBar und setBar) und ein Keyword namens 'property' oder so ähnlich setzt. Später kann diese Property wie ein normales Feld benutzt werden; Zuweisungen erfolgen also normal mit z.B. 'Foo.Bar = 5' und Lesezugriffe auch wie gehabt mit z.B. 'Print Foo.Bar'. Beim übersetzen aber werden Zuweisungen und Lesezugriffe durch Aufrufe der entsprechenden Setter und Getter ersetzt. Der Vorteil? Ich zitiere aus Wikipedia Zitat:
Nachdem die Funktionsüberladung abgeschlossen ist, werde ich mich aber wohl eher wieder den Zeigern, expliziten Casts etc. zuwenden, damit ich überhaupt beliebigen BMax-Code vollständig durchparsen kann.
Folgendes Beispiel BlitzMax: [AUSKLAPPEN]
Type TFoo
Method Bar( A:Float )
Print "Float!"
EndMethod
Method Bar( A:Int )
Print "Int!"
EndMethod
Method Bar( A:String )
Print "String!"
End Method
End Type
Local Foo:TFoo = New TFoo
Foo.Bar( 0.5 )
Foo.Bar( 1 )
Foo.Bar( "Hello world!" )
Wie man sieht, wählt der Precompiler automatisch die richtige überladene Variante, wenn die Parametertypen exakt übereinstimmen.
Was aber, wenn die Typen nicht exakt übereinstimmen? BlitzMax: [AUSKLAPPEN]
Type TFoo
Method Bar( A:Float, B:String )
EndMethod
Method Bar( A:TFoo, B:String )
EndMethod
End Type
Local Foo:TFoo = New TFoo
Foo.Bar( 23.0!, 42 ) 'Double lässt sich unter anderem nach Float casten, Int unter anderem nach String
'Double lässt sich nicht nach TFoo casten
'--> Erste Methode wird aufgerufen
Wichtig ist aber, dass Funktionen, die genau zutreffen, Vorrang haben vor Funktionen, die über Casting zutreffen würden BlitzMax: [AUSKLAPPEN]
Type TFoo
Method Bar( A:Float, B:Int = 3 )
EndMethod
Method Bar( A:Float )
EndMethod
Method Bar( A:Int )
EndMethod
End Type
Local Foo:TFoo = New TFoo
Foo.Bar( 0.5 ) 'Alle drei Methoden würden zutreffen. Da aber Bar( float ) genau der Signatur der zweiten Methode entspricht, wird diese aufgerufen
Foo.Bar( 1 ) 'Wieder dasselbe, nur wird diesmal die dritte ausgewählt
Foo.Bar( 0.5! ) 'Fehler! Keine Methode passt genau auf Bar( double ). Durch casting bzw. weglassen von optionalen Parametern treffen aber alle zu
'---> Fehlermeldung "Overloaded function 'Bar' is ambiguous (in line 17)"
Interessantes Verhalten lässt sich ausserdem feststellen, wenn man Funktionen und Methoden überlädt BlitzMax: [AUSKLAPPEN]
Type TFoo
'Auch wenn hier je eine Methode und eine Funktion vorliegen, dürfen sie nicht die exakt gleiche Signatur haben
Method Bar( A:Int, B:Int = 3 )
EndMethod
Function Bar( A:Int )
EndFunction
End Type
Local Foo:TFoo = New TFoo
Foo.Bar( 1 ) 'Statische Funktion wird aufgerufen
Foo.Bar( 1, 1 ) 'Methode wird aufgerufen
TFoo.Bar( 1 ) 'Statische Funktion wird aufgerufen
TFoo.Bar( 0.5 ) 'Es treffen zwar beide Funktionssignaturen durch einen Cast zu, da aber von aussen nur die statische Funktion sichtbar ist, wird diese aufgerufen
Foo.Bar( 0.5 ) 'Fehler! Keine der beiden Funktionssignaturen trifft exakt zu, allerdings würden beide durch einen Cast von 0.5 wieder passen. Da hier nun sowohl die statische Funktion als auch die Methode sichtbar sind, beschwert sich der Precompiler
Verwirrend? Das ist es in der Tat. Aber aus Gründen der Sauberkeit sollte man sowas auch vermeiden.
Ein letztes Beispiel habe ich noch, das mit abgeleiteten Types funktioniert. Hier lassen sich wieder dieselben Verhaltensregeln beobachten BlitzMax: [AUSKLAPPEN]
Type TA
End Type
Type TB Extends TA
End Type
Type TC Extends TB
End Type
Type TFoo
Method Bar:Int( A:TA )
End Method
Method Bar:Int( B:TB )
End Method
End Type
Local Foo:TFoo = New TFoo
Foo.Bar( New TA ) 'Die erste Methode trifft als einzige zu
Foo.Bar( New TB ) 'Die zweite Methode trifft exakt zu. Da sich TB auch nach TA casten lässt, würde die erste Methode auch über einen Cast erreichbar sein, aber wie immer haben exakte Treffer Vorrang vor Cast-Treffern
Foo.Bar( New TC ) 'Fehler! Keine Methode trifft exakt zu, aber TC lässt sich sowohl nach TA als auch nach TB casten, sprich, über einen impliziten Cast treffen beide zu.
Das Übersetzen ist dann weniger spektakulär. Funktionsnamen werden umgewandelt, indem an den Namen noch die Parametertypen in Kurzform angehängt werden. Der Aufruf wird auch umgewandelt, wobei das Programm per Backtracking bestimmt, von wo der Funktionszeiger herkommt. So könnte man auch den Funktionsnamen ausklammern und so Zeug, wie folgendes Beispiel unter anderem auch zeigt BlitzMax: [AUSKLAPPEN]
SuperStrict
Type TA
End Type
Type TB Extends TA
End Type
Type TC Extends TB
End Type
Type TFoo
Method Bar( A:Float )
EndMethod
Method Bar( A:Int )
EndMethod
Method Bar( A:String )
End Method
Method Bar( A:Float, B:String )
EndMethod
Method Bar( A:Int, B:Int = 3 )
EndMethod
Method Bar:Int( A:TA )
End Method
Method Bar:Int( B:TB )
End Method
End Type
Local Foo:TFoo = New TFoo
Foo.Bar( 0.5 )
Foo.Bar( 0.5, "Trololololo" )
Foo.Bar( New TA )
Foo.Bar( New TB )
( Foo.Bar )( 42, "Das sowas überhaupt geht!" ) 'Foo.Bar liefert den (überladenen) Funktionszeiger zurück, welcher durch die anschliessenden Klammern aufgerufen wird. Trotzdem kann der Precompiler den Ursprung des Zeigers bestimmen und den entsprechenden Bezeichner umbenennen.
Das wird dann übersetzt in den folgenden Code BlitzMax: [AUSKLAPPEN]
SuperStrict
Type TA
EndType
Type TB Extends TA
EndType
Type TC Extends TB
EndType
Type TFoo
Method Bar_f( A:Float )
EndMethod
Method Bar_i( A:Int )
EndMethod
Method Bar_s( A:String )
EndMethod
Method Bar_f_s( A:Float, B:String )
EndMethod
Method Bar_i_i( A:Int, B:Int = 3 )
EndMethod
Method Bar_ta:Int( A:TA )
EndMethod
Method Bar_tb:Int( B:TB )
End EndMethod
EndType
Local Foo:TFoo = New TFoo
Foo.Bar_f( 0.5 )
Foo.Bar_f_s( 0.5, "Trololololo" )
Foo.Bar_ta( New TA )
Foo.Bar_tb( New TB )
( Foo.Bar_f_s )( 42, "Das sowas überhaupt geht!" ) 'Foo.Bar liefert den (überladenen) Funktionszeiger zurück, welcher durch die anschliessenden Klammern aufgerufen wird. Trotzdem kann der Precompiler den Ursprung des Zeigers bestimmen und den entsprechenden Bezeichner umbenennen.
Man beachte, dass der Rückgabetyp nicht im Funktionsnamen steckt und daher Funktionen mit gleichen Parametertypen, aber unterschiedlichen Rückgabetypen nicht erlaubt sind. Zu bestimmen, welcher Rückgabetyp erwartet wird, ist relativ schwierig umzusetzen.
Bis anhin kann man nur Funktionen und Methoden in Types überladen, dass muss ich noch mit einem kleinen Fix auch für normale Funktionen erlauben. Ausserdem funktioniert die Überladung noch nicht, wenn ein abgeleiteter Type die Methoden seiner Basisklasse überlädt - da muss noch was getan werden.
Ein neues Feature ist mir eingefallen, das ich wohl auch implementieren werde - Properties. Im Prinzip geht es darum, dass man für irgendein Field (z.B. Bar) die passenden Getter und Setter schreibt (hier also getBar und setBar) und ein Keyword namens 'property' oder so ähnlich setzt. Später kann diese Property wie ein normales Feld benutzt werden; Zuweisungen erfolgen also normal mit z.B. 'Foo.Bar = 5' und Lesezugriffe auch wie gehabt mit z.B. 'Print Foo.Bar'. Beim übersetzen aber werden Zuweisungen und Lesezugriffe durch Aufrufe der entsprechenden Setter und Getter ersetzt. Der Vorteil? Ich zitiere aus Wikipedia Zitat:
The field-like syntax is said to be easier to read and write than lots of method calls, yet the interposition of method calls allows for data validation, active updating (as of GUI visuals), and/or read-only 'fields'.
Nachdem die Funktionsüberladung abgeschlossen ist, werde ich mich aber wohl eher wieder den Zeigern, expliziten Casts etc. zuwenden, damit ich überhaupt beliebigen BMax-Code vollständig durchparsen kann.
Konstruktoren und Private/Public abgeschlossen
Die Fehler, die wie im letzten Eintrag angesprochen noch überprüft werden mussten, sind nun auch fertig implementiert. Wer also eines der folgenden Konstrukte in seinem Code verwendet, bekommt an den mit 'Fehler!' kommentierten Stellen eine Meldung um die Ohren geschmissen BlitzMax: [AUSKLAPPEN]
Wie man aus dem obigen Code vielleicht erkennen kann, ist Return ohne angegebenen Wert erlaubt (und wird dann einfach in 'Return Self' übersetzt). Schliesslich sollte man ja auch aus einem Konstruktor frühzeitig mit Return zurückkehren können, falls es nötig ist.
Desweiteren baute ich heute morgen noch schnell die Private/Public-Sache vollständig ein. Diese verhalten sich genau wie in anderen Sprachen BlitzMax: [AUSKLAPPEN]
In einem Type darf es selbstverständlich mehrere Private/Public-Sektionen geben, wobei Konstruktoren nur im Public-Teil stehen dürfen. Types beginnen standardmässig Public.
Die Übersetzung in 'normalen' BMax-Code erfolgt nach Codekonvention, sprich ein Unterstrich vor privaten Variablen/Methoden/Funktionen. Obiger, übersetzter Code (ohne die fehlerhaften Teile, natürlich) BlitzMax: [AUSKLAPPEN]
Wie man sieht, werden die entsprechenden Token von Private/Public beim ausgeben einfach ignoriert. Das resultiert in einer vielleicht ein wenig unästhetischen Leerzeile, aber damit wird man wohl leben müssen.
Nächster Stop: Funktionsüberladung!
Type TFoo
Method New()
End Method
Method New( A:Int, B:Int = 3, C:Int ) 'Fehler!
EndMethod
EndType
Type TBar
Method Constructor( A:Int, B:Int ) 'Fehler
End Method
End Type
Type TFubar
Method New( A:Int, B:Int, C:Int )
Return A + B + C 'Fehler!
End Method
End Type
Type TZar
Method New( A:Int, B:Int, C:Int )
If A = 4 Then Return 'Erlaubt
Print A + B + C
End Method
End Type
Wie man aus dem obigen Code vielleicht erkennen kann, ist Return ohne angegebenen Wert erlaubt (und wird dann einfach in 'Return Self' übersetzt). Schliesslich sollte man ja auch aus einem Konstruktor frühzeitig mit Return zurückkehren können, falls es nötig ist.
Desweiteren baute ich heute morgen noch schnell die Private/Public-Sache vollständig ein. Diese verhalten sich genau wie in anderen Sprachen BlitzMax: [AUSKLAPPEN]
Type TFoo
Private
Field A:Int, B:Int
Field C:String = "Hello, World!"
Method printC()
Print C
End Method
Public
Field D:Int = 42
Method getC:Int()
Return C
End Method
End Type
Local Foo:TFoo = New TFoo
Print Foo.getC()
Print Foo.D
Foo.printC() 'Fehler!
Print Foo.A 'Fehler!
Print Foo.B 'Fehler!
In einem Type darf es selbstverständlich mehrere Private/Public-Sektionen geben, wobei Konstruktoren nur im Public-Teil stehen dürfen. Types beginnen standardmässig Public.
Die Übersetzung in 'normalen' BMax-Code erfolgt nach Codekonvention, sprich ein Unterstrich vor privaten Variablen/Methoden/Funktionen. Obiger, übersetzter Code (ohne die fehlerhaften Teile, natürlich) BlitzMax: [AUSKLAPPEN]
Type TFoo
Field _A:Int, _B:Int
Field _C:String = "Hello, World!"
Method _printC()
Print _C
End Method
Field D:Int = 42
Method getC:Int()
Return _C
End Method
End EndType
Local Foo:TFoo = New TFoo
Print Foo.getC()
Print Foo.D
Wie man sieht, werden die entsprechenden Token von Private/Public beim ausgeben einfach ignoriert. Das resultiert in einer vielleicht ein wenig unästhetischen Leerzeile, aber damit wird man wohl leben müssen.
Nächster Stop: Funktionsüberladung!
Erste Ergebnisse
Da ich ja seit nun zwei Wochen im Praktikum stecke und mir nach 8 Stunden Programmierung abends der Sinn nicht mehr besonders nach noch mehr Geschreibe steht, kam der Precompiler auch nur langsam voran. Zeiger zu implementieren war mir dann auch ein wenig öde, also bin ich auf der Todo-Liste schnurstracks zu den Konstruktoren gesprungen.
Syntax: BlitzMax: [AUSKLAPPEN]
Der Precompiler wandelt dann nach festgesetzten Regeln um. Das obere Beispiel wird dann in folgenden Code umgewandelt (die Kommentare habe ich nachher von Hand durch andere ersetzt - normalerweise würden die obigen Kommentare natürlich auch erhalten werden): BlitzMax: [AUSKLAPPEN]
Hier noch ein kleiner Beispielcode von Fehlern, die nun als solche erkannt werden BlitzMax: [AUSKLAPPEN]
Dass man die Methode Constructor nicht selber definieren sollte und in New auch kein Return verwenden darf, sollte klar sein. Als Fehler erkannt wird das noch nicht, wird aber bald eingebaut.
Soviel zu dem.
Heutiger Ohrgasmus: Justice
Syntax: BlitzMax: [AUSKLAPPEN]
Type TFoo
Method New( A:Int, B:Int = 4, C:Int ) 'Optionale Parameter gehen natürlich
Print A + C + D
End Method
End Type
Local Foo1:TFoo = New TFoo( 3, 4, 9 )
Local Foo2:TFoo = New TFoo( 3,, 9 ) 'Parameter auslassen funktioniert genau wie bei normalen Methoden
Type TBar
Method New()
Print "Wenigstens noch ein leerer Konstruktor"
End Method
End Type
Local Bar1:TBar = New TBar()
Local Bar2:TBar = New TBar 'Da der Konstruktor keine Parameter verlangt, ist auch das hier erlaubt
Type TFubar
End Type
Local Fubar1:TFubar = New TFubar
Local Fubar2:TFubar = New TFubar() 'Klammern werden auch akzeptiert, wenn im Type kein New definiert wurde
Der Precompiler wandelt dann nach festgesetzten Regeln um. Das obere Beispiel wird dann in folgenden Code umgewandelt (die Kommentare habe ich nachher von Hand durch andere ersetzt - normalerweise würden die obigen Kommentare natürlich auch erhalten werden): BlitzMax: [AUSKLAPPEN]
Type TFoo
'New mit Parameter wird in 'Constructor' mit entsprechendem Datentyp und 'Return Self' am Ende umgewandelt
Method Constructor:TFoo( A:Int, B:Int = 4, C:Int )
Print A + C + D
Return Self
EndMethod
EndType
Local Foo1:TFoo = New TFoo.Constructor( 3, 4, 9 ) 'Konstruktorenaufrufe werden auch passend umgewandelt
Local Foo2:TFoo = New TFoo.Constructor( 3,, 9 )
Type TBar
Method New() 'Um die Lesbarkeit zu erhöhen, werden Konstruktoren ohne Parameter bei 'New' belassen
Print "Wenigstens noch ein leerer Konstruktor"
EndMethod
EndType
Local Bar1:TBar = New TBar 'Klammern bei Konstruktoren ohne Parameter werden verworfen
Local Bar2:TBar = New TBar
Type TFubar
EndType
Local Fubar1:TFubar = New TFubar
Local Fubar2:TFubar = New TFubar 'Selbes wie bei TBar
Hier noch ein kleiner Beispielcode von Fehlern, die nun als solche erkannt werden BlitzMax: [AUSKLAPPEN]
Type TFoo
Method New:Int() 'Fehler!
End Method
End Type
Type TBar
Method New( A:Int, B:Int, C:Int )
End Method
End Type
New TBar 'Fehler!
New TBar() 'Fehler!
New TBar( 1, 2 ) 'Fehler!
'etc. etc.
Dass man die Methode Constructor nicht selber definieren sollte und in New auch kein Return verwenden darf, sollte klar sein. Als Fehler erkannt wird das noch nicht, wird aber bald eingebaut.
Soviel zu dem.
Heutiger Ohrgasmus: Justice
Der BMax Precompiler
Während des letzten Monats habe ich an einem neuen Projekt geschraubt, welches mir schon lange im Kopf herumschwirrte: Ein BMax Precompiler.
In diesem und im englischen Forum wurden schon lange Wünsche geäussert, dass BMax doch ein paar Zusatzfeatures bekäme. Vor allem geht es dabei um echte Konstruktoren, Funktionsüberladung, echtes Private/Public und Operatorenüberladung.
Da Mark aber scheinbar ziemlich viel anderes im Kopf hat (zuerst Max3D, jetzt BMX 2), wird man wohl noch lange auf diese Features warten müssen. Daher hatte ich mir zum Ziel gesetzt, einen Precompiler zu schreiben, der sich nahtlos zwischen BMK und BCC einfügt und 'erweiterten' BMax-Code umwandelt in 'echten' BMax-Code, der nachher vom BCC kompiliert wird.
Der Hauptgedanke hinter dem Precompiler ist, dass er trotz Umwandlung einen lesbaren Code produziert, damit Debugging immer noch möglich ist und man den Vorkompilierten Code auch an andere weitergeben kann, die den Precompiler nicht besitzen. Zu diesem Zweck erhält der Precompiler die Originalformatierung zu 100% - sprich, Tabs, Leerschläge, Gross/Kleinschreibung etc. werden alle erhalten. Features, die das Originale BMax nicht beherrscht, werden so lesbar wie möglich umgewandelt.
Was besonders wichtig ist, dass der Precompiler alle Syntax-Fehler, die im Code stecken könnten, abfängt. Falls er Syntax-Fehler ignoriert und sie einfach an den BCC weiterreicht oder aufgrund inkorrekten Codes abstürzt, wird es für den User relativ umständlich, die entsprechenden Fehler zu finden. Das ist natürlich eine nicht ganz leichte Aufgabe, aber im Moment kommt es recht gut voran.
Wie ist denn der aktuelle Stand?
Nun, im Moment ist das Grundgerüst fertig und ziemlich stabil. Die funktionierenden Teile arbeiten wie folgt:
Wie man feststellt, ist das ein Multi-Passcompiler mit drei Durchläufen. Ab dem ersten Durchlauf sind alle Datentypen, die vorkommen können, bekannt (sprich, primitive Datentypen wie Int, Float etc. und die definierten Types). Ab dem zweiten Durchlauf sind alle Funktionen bekannt sowie alle Member der Types, auf die zugegriffen werden kann. Im schwierigsten und wichtigste Durchlauf, Nummer 3, wird dann erst der tatsächliche Code analysiert und auf Korrektheit geprüft. Die einzelnen Codestücke werden dort in drei Kategorien eingeteilt:
All das funktioniert schon alles fast vollständig. Kontrollstrukturen sind in allen Variationen komplett eingebaut (naja, bis auf EachIn), Deklarationen sind fertig und Statements bis auf einige Ausnahmen ebenfalls.
Was noch nicht implementiert ist, sind Zeiger (Sowohl Byte/Float/usw. Ptr als auch Funktionszeiger), Konstanten (Pi, Null), Typecasts und ziemlich viele Keywords wie etwa Incbin, Release, GoTo, Data etc. Als Hauptpriorität habe ich mir gesetzt, Zeiger, Typecasts und die fehlenden Konstanten zu implementieren und dann zu den Zusatzfeatures überzugehen. Die fehlenden Keywords müssen zwar früher oder später noch rein, aber da ich sie selten benötige, schiebe ich diese langweilige Aufgabe noch ein wenig nach hinten.
So ein Precompiler wäre natürlich sinnlos, wenn er nicht ein paar neue Features zur Sprache hinzufügt. Ich habe im Moment die folgenden eingeplant (in der Reihenfolge):
Leider kommt das Projekt nicht mehr so schnell voran wie am Anfang, da ich nächsten Donnerstag ein Praktikum anfange und vorher noch Groovy (ein Java-Dialekt *schauder*) lernen muss, was mehr oder weniger meine ganze Zeit auffrisst. Ich hoffe aber, dass ich das Projekt noch zufriedenstellend fertigstellen kann.
Was die Vertreibung angeht, halte ich mir im Hinterkopf, den Precompiler nachher für einen kleinen Geldbetrag (5$-10$) zu vertreiben. Vorher muss sich aber noch herausstellen, ob die Leute überhaupt bereit sind, für so ein Programm zu zahlen - hat ja keinen Wert, den ganzen Aufwand zu betreiben und nachher nur ein Exemplar an seine Mutter zu verkaufen
In diesem und im englischen Forum wurden schon lange Wünsche geäussert, dass BMax doch ein paar Zusatzfeatures bekäme. Vor allem geht es dabei um echte Konstruktoren, Funktionsüberladung, echtes Private/Public und Operatorenüberladung.
Da Mark aber scheinbar ziemlich viel anderes im Kopf hat (zuerst Max3D, jetzt BMX 2), wird man wohl noch lange auf diese Features warten müssen. Daher hatte ich mir zum Ziel gesetzt, einen Precompiler zu schreiben, der sich nahtlos zwischen BMK und BCC einfügt und 'erweiterten' BMax-Code umwandelt in 'echten' BMax-Code, der nachher vom BCC kompiliert wird.
Der Hauptgedanke hinter dem Precompiler ist, dass er trotz Umwandlung einen lesbaren Code produziert, damit Debugging immer noch möglich ist und man den Vorkompilierten Code auch an andere weitergeben kann, die den Precompiler nicht besitzen. Zu diesem Zweck erhält der Precompiler die Originalformatierung zu 100% - sprich, Tabs, Leerschläge, Gross/Kleinschreibung etc. werden alle erhalten. Features, die das Originale BMax nicht beherrscht, werden so lesbar wie möglich umgewandelt.
Was besonders wichtig ist, dass der Precompiler alle Syntax-Fehler, die im Code stecken könnten, abfängt. Falls er Syntax-Fehler ignoriert und sie einfach an den BCC weiterreicht oder aufgrund inkorrekten Codes abstürzt, wird es für den User relativ umständlich, die entsprechenden Fehler zu finden. Das ist natürlich eine nicht ganz leichte Aufgabe, aber im Moment kommt es recht gut voran.
Wie ist denn der aktuelle Stand?
Nun, im Moment ist das Grundgerüst fertig und ziemlich stabil. Die funktionierenden Teile arbeiten wie folgt:
- 1. Quelltext einlesen und in einen abstrakten Parsetree umwandeln. Die entfernten Whitespaces werden für den späteren Gebrauch zwischengespeichert.
- 2. Erster Durchlauf durch den Quelltext: Frameworks, Imports und den Strict-Mode herausparsen. Von allen Types ihre Namen zwischenspeichern.
- 3. Aus allen importierten Modulen die Interface-Dateien heraussuchen und parsen: Alle Funktionen, Types, Methoden, Globale, Konstanten etc. herausparsen und zwischenspeichern.
- 4. Zweiter Durchlauf durch den Quelltext: Alle globalen Funktionen und alle Funktionen, Globalen, Fields, Konstanten und Methoden in Types herausparsen und zwischenspeichern.
- 5. Dritter und letzter Durchlauf durch den Quelltext: Den ganzen Code ablaufen und die einzelnen Anweisungen auf Korrektheit überprüfen.
- 6. Den abstrakten Parsetree mithilfe der gespeicherten Whitespaces wieder in den ursprünglichen Code umwandeln und ausgeben
Wie man feststellt, ist das ein Multi-Passcompiler mit drei Durchläufen. Ab dem ersten Durchlauf sind alle Datentypen, die vorkommen können, bekannt (sprich, primitive Datentypen wie Int, Float etc. und die definierten Types). Ab dem zweiten Durchlauf sind alle Funktionen bekannt sowie alle Member der Types, auf die zugegriffen werden kann. Im schwierigsten und wichtigste Durchlauf, Nummer 3, wird dann erst der tatsächliche Code analysiert und auf Korrektheit geprüft. Die einzelnen Codestücke werden dort in drei Kategorien eingeteilt:
- Kontrollstruktur: If, For, While, Select, Repeat etc. Eröffnet je nach Strictmodus einen neuen Scope
- Deklaration: Mit oder ohne Local, je nach Strictmodus. Fügt die neue Variable zum aktuellen Scope hinzu
- Statement: Funktionsaufruf mit oder ohne Klammern, Zuweisung
All das funktioniert schon alles fast vollständig. Kontrollstrukturen sind in allen Variationen komplett eingebaut (naja, bis auf EachIn), Deklarationen sind fertig und Statements bis auf einige Ausnahmen ebenfalls.
Was noch nicht implementiert ist, sind Zeiger (Sowohl Byte/Float/usw. Ptr als auch Funktionszeiger), Konstanten (Pi, Null), Typecasts und ziemlich viele Keywords wie etwa Incbin, Release, GoTo, Data etc. Als Hauptpriorität habe ich mir gesetzt, Zeiger, Typecasts und die fehlenden Konstanten zu implementieren und dann zu den Zusatzfeatures überzugehen. Die fehlenden Keywords müssen zwar früher oder später noch rein, aber da ich sie selten benötige, schiebe ich diese langweilige Aufgabe noch ein wenig nach hinten.
So ein Precompiler wäre natürlich sinnlos, wenn er nicht ein paar neue Features zur Sprache hinzufügt. Ich habe im Moment die folgenden eingeplant (in der Reihenfolge):
- Echte Konstruktoren: Im Prinzip die New-Methode mit Parametern, welche man beim Erstellen zwingend angeben muss. Beispiel BlitzMax: [AUSKLAPPEN]
Type TFoo
Method New( A:Int, B:Int )
Print A + B
End Method
End Type
Local Foo:TFoo = New TFoo( A, B )
Foo = New TFoo 'Fehler!
Dies hat den Vorteil, dass man den Konstruktor nicht vermeiden kann wie jetzt. Zwar wird oft 'Create' als Pseudokonstruktor verwendet, welchen man aber ohne weiteres umgehen kann, indem man ihn einfacht nicht aufruft. Darum ist ein Pflichtkonstruktor mit Parametern von Vorteil
- Echtes Private/Public: Das jetzige Private/Public ist nicht zu gebrauchen, da es etwas komplett anderes tut, als man es von anderen Programmiersprachen kennt. Das sollte sich ändern.
- Funktionsüberladung: Das ist natürlich eine etwas schwierigere Aufgabe. Der aktuelle Ausdrucksparser kann zwar mit absoluter Sicherheit den Datentyp bestimmen, der bei einem Ausdruck nach Ausführung herauskommt (was für Funktionsüberladung zwingend ist), jedoch macht die schwache Typisierung von BMax das ganze etwas schwieriger. Folgendes Beispiel BlitzMax: [AUSKLAPPEN]
Function Add:Int( A:Int, B:Int )
Return A + B
End Function
Function Add:Float( A:Float, B:Float )
Return A + B
End Function
Print Add( 3, 3.4 ) 'Welche Funktion soll nun aufgerufen werden? Die Parametertypen entsprechen keiner Funktion, können aber ohne weiteres in die erwarteten Typen ungewandelt werden - für beide Funktionen.
In so einem Fall wird der Compiler wohl eine Fehlermeldung ausgeben müssen, dass er sich nicht entscheiden kann - für absolute Sicherheit wird man wohl die Parameter explizit in die Typen umcasten müssen, die der Funktion entsprechen, die man aufrufen will.
Leider kommt das Projekt nicht mehr so schnell voran wie am Anfang, da ich nächsten Donnerstag ein Praktikum anfange und vorher noch Groovy (ein Java-Dialekt *schauder*) lernen muss, was mehr oder weniger meine ganze Zeit auffrisst. Ich hoffe aber, dass ich das Projekt noch zufriedenstellend fertigstellen kann.
Was die Vertreibung angeht, halte ich mir im Hinterkopf, den Precompiler nachher für einen kleinen Geldbetrag (5$-10$) zu vertreiben. Vorher muss sich aber noch herausstellen, ob die Leute überhaupt bereit sind, für so ein Programm zu zahlen - hat ja keinen Wert, den ganzen Aufwand zu betreiben und nachher nur ein Exemplar an seine Mutter zu verkaufen
Multithreading <3
Heute hab ich nochmal einen kleinen Test zusammengeworfen, um das neu implementierte Multithreading in der Photon Map, dem Raytracer und dem SPH-Simulator auf die Probe zu stellen. Die Anzahl Photonen pro Frame wurde verzehnfacht und die Anzahl SPH-Partikel mehr als verdoppelt, aber trotzdem renderte das Video bei der gleichen Anzahl Frames mehr als doppelt so schnell in 1h 50min. Damit werde ich mich wohl zufriedengeben, obwohl die SPH-Partikel wohl noch ein wenig optimaler auf die Threads aufgeteilt werden könnten.

Der Wasserstrom aus der Röhre sieht nun hoffentlich nicht mehr nach einem 'Eisstrahl' aus wie im letzten Video
Als nächstes werde ich mir wohl was einfallen lassen müssen, wie ich denn Wandpartikel möglichst effizient und hübsch auf den Bildschirm bringe, damit ich die Szene mit Hindernissen für das Wasser aufpeppen kann.
Der Wasserstrom aus der Röhre sieht nun hoffentlich nicht mehr nach einem 'Eisstrahl' aus wie im letzten Video
Als nächstes werde ich mir wohl was einfallen lassen müssen, wie ich denn Wandpartikel möglichst effizient und hübsch auf den Bildschirm bringe, damit ich die Szene mit Hindernissen für das Wasser aufpeppen kann.
Multithreading
Ich machte heute erste Versuche mit Multithreading im SPH-Code. Multithreading ist in BMax bei so vielen Objekten zwar unbrauchbar (der veränderte GC im Multithreading verlangsamt das Programm um einiges mehr, als dass ich mit mehreren Threads wieder rausholen könnte), aber da die SPH-Berechnungen nun sowieso in C++ ablaufen, setzte ich das Multithreading mit der WinAPI um.
Um die grösste Geschwindigkeit herauszuholen, verzichtete ich komplett auf Mutexe bzw. Semaphoren, um zu verhindern, dass ein Thread auf die anderen warten muss. Stattdessen werden alle Situationen vermieden, in denen sich möglicherweise zwei Schreibprozesse überschneiden könnten. Das bedeutet, dass das Programm eher in Kauf nimmt, etwas später nochmal neu berechnen zu müssen, als die Änderungen direkt zu übertragen, was in einer Überschneidung von zwei Threads führen könnte.
Das führt dazu, dass es je nach Partikelanzahl eine optimale Threadanzahl gibt. Mehr Threads als die optimale Anzahl verlangsamen also das Programm, obwohl mehr Kerne ausgelastet werden Da ich im Raytracer nachher aber meistens gigantische Partikelanzahlen habe, ist die optimale Threadanzahl sowieso immer die Anzahl Kerne der CPU, also mache ich mir da keine Sorgen.
Mit Multithreading ist die 3D-Version sogar Echtzeitfähig, daher habe ich eine kleine Demo aus dem C++-Projekt geschnürt. Ich hoffe, es ist erlaubt, dass ich hier ein C++-Programm poste, aber der Code wird ja nachher in einem BMax-Projekt verwendet, daher wird hier hoffentlich noch ein Auge zugedrückt.
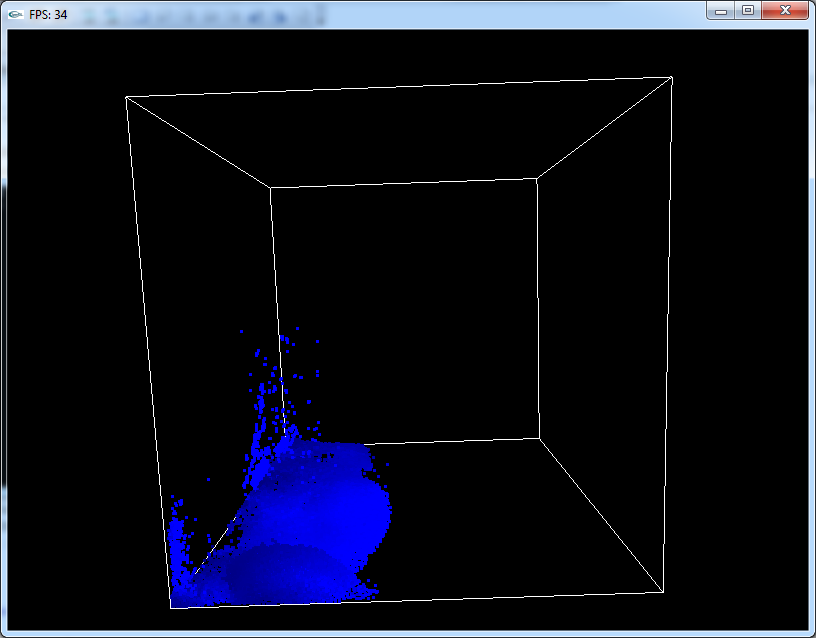
Download: Link
Die Bedienung erfolgt mit den Pfeiltasten, mit denen man den Würfel drehen kann. Da die Gravitation immer nach unten zieht, kann man so mit der Flüssigkeit rumspielen. Am Anfang wird man nach der Anzahl Threads gefragt, die verwendet werden sollen. Dort gibt man am besten die Anzahl Kerne an, die die CPU hat, oder 4, wenn man mehr als 4 Kerne hat (4 ist die optimale Anzahl Threads bei 16'000 Partikeln).
Als nächstes werde ich den Raytracer vermultithreadisieren, was die Geschwindigkeit hoffentlich um einiges erhöht. Hirngespinst des Tages ist 1 FPS beim Rendern Mal sehen, ob ich das hinbekomme.
Um die grösste Geschwindigkeit herauszuholen, verzichtete ich komplett auf Mutexe bzw. Semaphoren, um zu verhindern, dass ein Thread auf die anderen warten muss. Stattdessen werden alle Situationen vermieden, in denen sich möglicherweise zwei Schreibprozesse überschneiden könnten. Das bedeutet, dass das Programm eher in Kauf nimmt, etwas später nochmal neu berechnen zu müssen, als die Änderungen direkt zu übertragen, was in einer Überschneidung von zwei Threads führen könnte.
Das führt dazu, dass es je nach Partikelanzahl eine optimale Threadanzahl gibt. Mehr Threads als die optimale Anzahl verlangsamen also das Programm, obwohl mehr Kerne ausgelastet werden
Mit Multithreading ist die 3D-Version sogar Echtzeitfähig, daher habe ich eine kleine Demo aus dem C++-Projekt geschnürt. Ich hoffe, es ist erlaubt, dass ich hier ein C++-Programm poste, aber der Code wird ja nachher in einem BMax-Projekt verwendet, daher wird hier hoffentlich noch ein Auge zugedrückt.
Download: Link
Die Bedienung erfolgt mit den Pfeiltasten, mit denen man den Würfel drehen kann. Da die Gravitation immer nach unten zieht, kann man so mit der Flüssigkeit rumspielen. Am Anfang wird man nach der Anzahl Threads gefragt, die verwendet werden sollen. Dort gibt man am besten die Anzahl Kerne an, die die CPU hat, oder 4, wenn man mehr als 4 Kerne hat (4 ist die optimale Anzahl Threads bei 16'000 Partikeln).
Als nächstes werde ich den Raytracer vermultithreadisieren, was die Geschwindigkeit hoffentlich um einiges erhöht. Hirngespinst des Tages ist 1 FPS beim Rendern
Photon Mapping Video
Ich habe heute einen kleinen Test zusammengeworfen, um die neuen Features zu testen. Dazugekommen sind Photon Mapping, Oberflächenspannung in 3D und jede Menge Speed (gerendert wird nun 5-7 Mal schneller als vorher). Entfernt habe ich einen sehr lästigen Bug, der mich knapp eine Woche Debugging gekostet hat (die Finger schwebten manchmal bedenklich lange über Ctrl+A, Delete und Ctrl+S).
Das Video findet ihr auf Youtube:

Photon Mapping braucht noch einiges an Kalibrierung, damit es realistisch aussieht (die Intensität schwankt immer noch ziemlich unschön), aber ich arbeite dran.
Das Video findet ihr auf Youtube:
Photon Mapping braucht noch einiges an Kalibrierung, damit es realistisch aussieht (die Intensität schwankt immer noch ziemlich unschön), aber ich arbeite dran.
Volume Rendering
Da ich in den letzten Wochen vor allem an meinem BCC-Beitrag arbeitete, wurde es in diesem Worklog leider ein wenig still. Um diesen Missstand zu beheben, werde ich heute ein wenig von meinem gestern fertiggestellten GPU-Volume-Renderer berichten.
Was ist denn Volume rendering schon wieder?
Im Volume rendering geht es ähnlich wie beim Voxel rendering darum, ein Voxelgitter zu rendern. Der Unterschied ist aber, dass im Volume rendering nicht beim ersten Voxel gestoppt wird, der einen gewissen Transparenzwert aufweist, sondern alle Voxel von hinten nach vorn ausgewertet werden, um die kombinierte Pixelfarbe nachher auf dem Bildschirm auszugeben.
Das Auswerten der Voxel erweist sich aber als ein wenig kompliziert. Volume Rendering wurde ursprünglich für die Medizin entwickelt, um Daten aus der Computertomographie darstellen zu können. Daher ist es wichtig, dass einzelne Gewebetypen herausgefiltert, während andere Gewebetypen ausgeblendet werden. Farbgebung und Beleuchtung spielen auch eine wichtige Rolle, um Form und Zusammensetzung des Gewebes besser zu erkennen. Ich werde die benötigten Formeln hier mal nicht erläutern - wer interessiert ist, kann sich ja mal diesen Artikel hier durchlesen.
Da es natürlich enorm kostspielig ist, jedes Voxel durch den Klassifikations-Algo zu schicken, werden alle Werte in BMax vorausberechnet und in eine passende Textur gesteckt. Aber auch so läuft das Programm enorm langsam - durchschnittlich 10 FPS bei 800x600 Pixeln. Das liegt daran, dass Normalen und Beleuchtung für jedes Voxel berechnet werden müssen, was bei entsprechend grossen Volumen ziemlich auf die Performance geht.
Als Testmodell diente der CT-Scan einer Freundin, der mir von ihr freundlicherweise zur Verfügung gestellt wurde. Auflösung liegt bei 512x512x256 Voxeln mit jeweils 12 Bit pro Voxel. Um den Wertebereich perfekt abzudecken, wurden zwei 4096x4096 Texturen verwendet, welche die vorausberechneten Werte dem Shader zur Verfügung zu stellen.
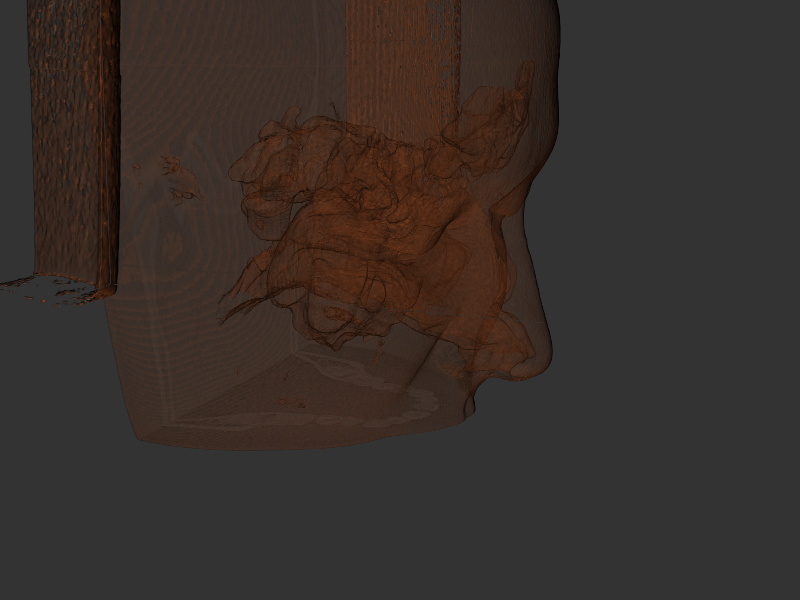
Hier noch ein paar Aufnahmen, um einen Eindruck vom Renderer zu geben:
Schädel:
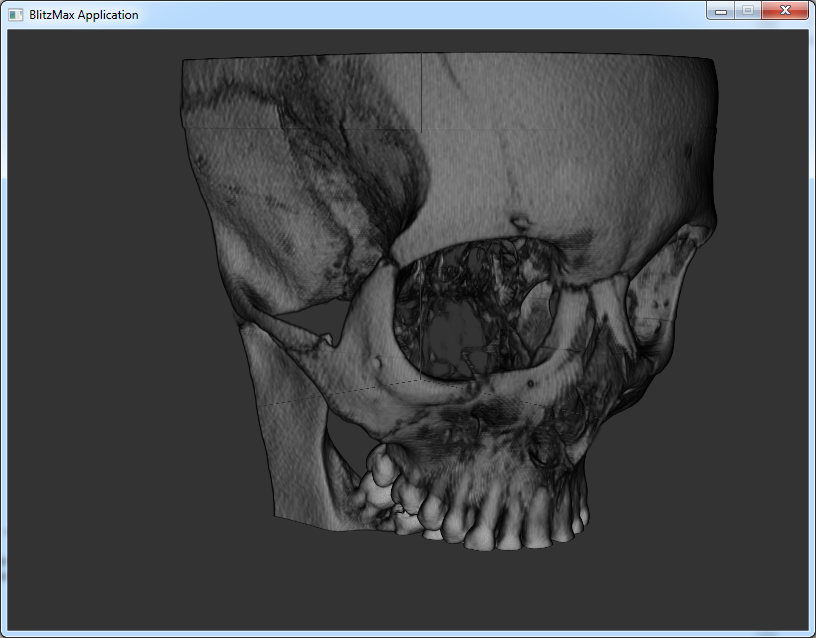
Nebenhöhlen:
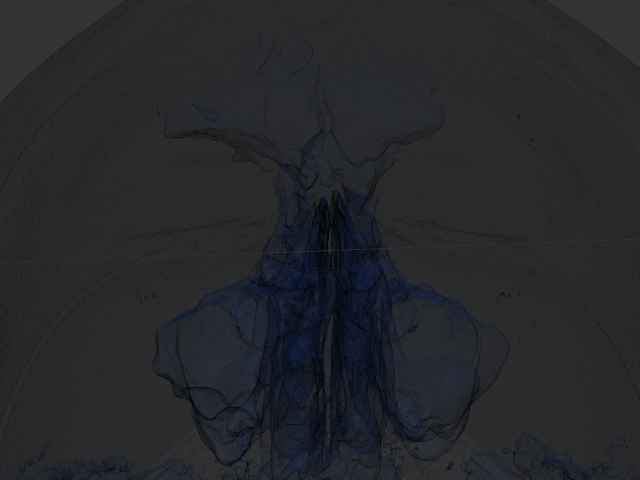
Youtube-Video: Link
Für diejenigen, die den Voxelrenderer im vorigen Eintrag aufgrund ihrer Hardware nicht ausprobieren konnten, habe ich ein Video dessen in Aktion hochgeladen: Link
Ab jetzt gehts wieder zurück ans Photon Mapping. Ein Video von Wasser mit Photon Mapping muss noch sein
PS: Ich liebe diesen Song. Von dem krieg ich Ohr-Orgasmen
Was ist denn Volume rendering schon wieder?
Im Volume rendering geht es ähnlich wie beim Voxel rendering darum, ein Voxelgitter zu rendern. Der Unterschied ist aber, dass im Volume rendering nicht beim ersten Voxel gestoppt wird, der einen gewissen Transparenzwert aufweist, sondern alle Voxel von hinten nach vorn ausgewertet werden, um die kombinierte Pixelfarbe nachher auf dem Bildschirm auszugeben.
Das Auswerten der Voxel erweist sich aber als ein wenig kompliziert. Volume Rendering wurde ursprünglich für die Medizin entwickelt, um Daten aus der Computertomographie darstellen zu können. Daher ist es wichtig, dass einzelne Gewebetypen herausgefiltert, während andere Gewebetypen ausgeblendet werden. Farbgebung und Beleuchtung spielen auch eine wichtige Rolle, um Form und Zusammensetzung des Gewebes besser zu erkennen. Ich werde die benötigten Formeln hier mal nicht erläutern - wer interessiert ist, kann sich ja mal diesen Artikel hier durchlesen.
Da es natürlich enorm kostspielig ist, jedes Voxel durch den Klassifikations-Algo zu schicken, werden alle Werte in BMax vorausberechnet und in eine passende Textur gesteckt. Aber auch so läuft das Programm enorm langsam - durchschnittlich 10 FPS bei 800x600 Pixeln. Das liegt daran, dass Normalen und Beleuchtung für jedes Voxel berechnet werden müssen, was bei entsprechend grossen Volumen ziemlich auf die Performance geht.
Als Testmodell diente der CT-Scan einer Freundin, der mir von ihr freundlicherweise zur Verfügung gestellt wurde. Auflösung liegt bei 512x512x256 Voxeln mit jeweils 12 Bit pro Voxel. Um den Wertebereich perfekt abzudecken, wurden zwei 4096x4096 Texturen verwendet, welche die vorausberechneten Werte dem Shader zur Verfügung zu stellen.
Hier noch ein paar Aufnahmen, um einen Eindruck vom Renderer zu geben:
Schädel:
Nebenhöhlen:
Youtube-Video: Link
Für diejenigen, die den Voxelrenderer im vorigen Eintrag aufgrund ihrer Hardware nicht ausprobieren konnten, habe ich ein Video dessen in Aktion hochgeladen: Link
Ab jetzt gehts wieder zurück ans Photon Mapping. Ein Video von Wasser mit Photon Mapping muss noch sein
PS: Ich liebe diesen Song. Von dem krieg ich Ohr-Orgasmen