Tokenizer & Co.


Halbzeit!
Ich habe eben die - hoffentlich - letzte Racer-Klasse fertiggestellt. (Ich hatte gar nicht an Labels gedacht.  )
)
Das Schreiben dieser Klassen war im Gegensatz zum ersten Versuch ziemlich angenehm, da ich schrittweise Arbeiten konnte und die Racer-Klassen voneinander unabhängig sind.
Leider bläht das erweiterbare Verfahren den Code etwas auf:
Code: [AUSKLAPPEN]
Der OOP-Overhead und die parallele Verarbeitung verlangsamen außerdem das Laden des Codes um den Faktor 4 auf etwas mehr als 500 ms bei 29 KiB Code. (5fache Ladezeit)
Das liegt aber meiner Meinung nach noch in einem erträglichen Zeitrahmen, da immerhin neue Möglichkeiten hinzugekommen sind. (Dazu gehört auch die Möglichkeit, Fehler zu entdecken.)
Hier ist die aktuelle Parser-Klasse für BlitzMax-Code.
BlitzMax: [AUSKLAPPEN]
Wie man sieht, sieht man eigentlich nur eine Auflistung der Möglichkeiten.
Ich habe wieder versucht, mich komplett an den von BlitzMax vorgegebenen Standard zu halten.
Deshalb gibt es hier KEINEN Fehler:
BlitzMax: [AUSKLAPPEN]
Als nächstes muss ich mir überlegen, wie ich die Struktur wieder zurückbringe.
Bis bald!
mpmxyz
Das Schreiben dieser Klassen war im Gegensatz zum ersten Versuch ziemlich angenehm, da ich schrittweise Arbeiten konnte und die Racer-Klassen voneinander unabhängig sind.
Leider bläht das erweiterbare Verfahren den Code etwas auf:
Code: [AUSKLAPPEN]
800 Zeilen
22,8 KiB
17 Klassen mit insgesamt 49 Methoden
22,8 KiB
17 Klassen mit insgesamt 49 Methoden
Der OOP-Overhead und die parallele Verarbeitung verlangsamen außerdem das Laden des Codes um den Faktor 4 auf etwas mehr als 500 ms bei 29 KiB Code. (5fache Ladezeit)
Das liegt aber meiner Meinung nach noch in einem erträglichen Zeitrahmen, da immerhin neue Möglichkeiten hinzugekommen sind. (Dazu gehört auch die Möglichkeit, Fehler zu entdecken.)
Hier ist die aktuelle Parser-Klasse für BlitzMax-Code.
BlitzMax: [AUSKLAPPEN]
Type TBMXParser Extends TCodeParser
Const TYP_SPACE:String="space"
Const TYP_NEWLINE:String="newline"
Const TYP_SYMBOL:String="symbol"
Const TYP_LABEL:String="label"
Const TYP_STRING:String="string"
Const TYP_IDENTIFIER:String="identifier"
Const TYP_INT:String="int"
Const TYP_HEX:String="hex"
Const TYP_BIN:String="bin"
Const TYP_FLOAT:String="float"
Const TYP_COMMENT:String="comment"
Const TYP_CONDITION:String="condition"
' Const TYP_:String="" 'zukünftige Erweiterungen
Method New()
AddRacer(New TSpaceRacer) 'Leerzeichen
AddRacer(New TLineRacer) 'Zeilenumbrüche
AddRacer(New TSymbolRacer) '+ - etc.
AddRacer(New TDoubleSymbolRacer) '<> :+ .. etc.
AddRacer(New TSymbolIdentifierRacer) ':Shl und Ähnliches
AddRacer(New TLabelRacer) 'Labels (NEU!)
AddRacer(New TStringRacer) 'Strings
AddRacer(New TIdentifierRacer) 'Identifier, wie "abc123"
AddRacer(New TDividedIdentifierRacer) 'getrennte Schreibweisen für z.B. "end if"
AddRacer(New TIntegerRacer) 'ganze Zahlen
AddRacer(New THexRacer) 'hexadezimale Angaben
AddRacer(New TBinRacer) 'binäre Angaben
AddRacer(New TFloatRacer) 'Gleitkommaangaben
AddRacer(New TCommentRacer) 'einzeilige Kommentare
AddRacer(New TRemRacer) 'mehrzeilige Kommentare
AddRacer(New TConditionRacer) 'Bedingungen, wie "?Debug" (NEU!)
EndMethod
EndType
Wie man sieht, sieht man eigentlich nur eine Auflistung der Möglichkeiten.
Ich habe wieder versucht, mich komplett an den von BlitzMax vorgegebenen Standard zu halten.
Deshalb gibt es hier KEINEN Fehler:
BlitzMax: [AUSKLAPPEN]
SuperStrict
Rem
Print "WTF?"
Als nächstes muss ich mir überlegen, wie ich die Struktur wieder zurückbringe.
Bis bald!
mpmxyz
ein Nachtrag
Inzwischen können BlitzMax-Strings, Leerzeichen und Identifier eingelesen werden.
Zu dem "Wettrenn-Algorithmus" möchte ich daher mal ein Beispiel zeigen.
Zu sehen ist einer der neuen "Rennfahrer":
BlitzMax: [AUSKLAPPEN]
Wie man schon am Namen erkennt, ist dieser Code für Identifier zuständig.
Hier ist übrigens der Pseudocode des eigentlichen Algorithmus:
Code: [AUSKLAPPEN]
Ich bin im Moment ziemlich zufrieden mit dem Ergebnis.
Immerhin habe ich jetzt auch eine bessere Möglichkeit, Syntaxfehler zu finden und zu melden.
Hierfür nutze ich die schon oben genannten Exceptions, welche sich auch aus der Funktion heraus leiten lassen.
Das war es erst einmal.
Zu den gestern schon angesprochenen Modulen und Codes verrate ich auch schon einmal etwas:
Die Probleme, ein Ziel zu treffen, sollten hiermit ein Ende haben.
Bis zum nächsten Eintrag!
mpmxyz
Zu dem "Wettrenn-Algorithmus" möchte ich daher mal ein Beispiel zeigen.
Zu sehen ist einer der neuen "Rennfahrer":
BlitzMax: [AUSKLAPPEN]
Type TIdentifierRacer Extends TCodeRacer
Field length:Int=0
Rem
bbdoc: gibt zurück, ob die Überprüfung weitergeführt werden soll
EndRem
Method Check:Int(char:String,parToken:TToken)
char=char.toLower()
If (char<>"_") 'von Anfang an erlaubte Zeichen: "_" und Buchstaben
If (char<"a") Or (char>"z")
If (char<"0") Or (char>"9") Or (length=0) 'nach dem Anfang erlaubt: Zahlen
Return False
EndIf
EndIf
EndIf
length:+1
Return True
EndMethod
Rem
bbdoc: gibt - wenn möglich - den Token zum angegebenen Code zurück, nachdem keiner der CodeRacer die Überprüfung für diesen Token fortführen möchte
EndRem
Method CreateToken:TToken(code:String,parToken:TToken)
If code.length=length
Return TToken.Create(TBMXParser.TYP_IDENTIFIER,Null,code)
EndIf
EndMethod
Rem
bbdoc: setzt den CodeRacer zurück
EndRem
Method Reset()
length=0
EndMethod
EndType
Wie man schon am Namen erkennt, ist dieser Code für Identifier zuständig.
Hier ist übrigens der Pseudocode des eigentlichen Algorithmus:
Code: [AUSKLAPPEN]
Gehe vom Startpunkt aus Zeichen für Zeichen vorwärts.
Überprüfe alle noch aktiven Rennfahrer und deaktiviere die, die nicht mehr weiter machen wollen. (->Check)
Wenn kein Rennfahrer aktiv ist...
Gehe Zeichen für Zeichen zurück, solange kein Token gefunden wurde. (wäre optimierbar)
Versuche, aus einem der deaktivierten Rennfahrer einen Token herauszubekommen, setze dann den Startpunkt neu und beende diese Schleife. (->CreateToken)
Wenn man wieder beim Startpunkt angekommen ist, wird das Parsen beendet und nach Wunsch eine Fehlermeldung ausgegeben bzw. nur Null zurückgegeben. (Exceptions aus den Rennfahrerobjekten werden auch nach Wunsch weitergeleitet.)
Setze alle Rennfahrer zurück. (->Reset)
Gebe die entstandene Tokenliste zurück.
Überprüfe alle noch aktiven Rennfahrer und deaktiviere die, die nicht mehr weiter machen wollen. (->Check)
Wenn kein Rennfahrer aktiv ist...
Gehe Zeichen für Zeichen zurück, solange kein Token gefunden wurde. (wäre optimierbar)
Versuche, aus einem der deaktivierten Rennfahrer einen Token herauszubekommen, setze dann den Startpunkt neu und beende diese Schleife. (->CreateToken)
Wenn man wieder beim Startpunkt angekommen ist, wird das Parsen beendet und nach Wunsch eine Fehlermeldung ausgegeben bzw. nur Null zurückgegeben. (Exceptions aus den Rennfahrerobjekten werden auch nach Wunsch weitergeleitet.)
Setze alle Rennfahrer zurück. (->Reset)
Gebe die entstandene Tokenliste zurück.
Ich bin im Moment ziemlich zufrieden mit dem Ergebnis.
Immerhin habe ich jetzt auch eine bessere Möglichkeit, Syntaxfehler zu finden und zu melden.
Hierfür nutze ich die schon oben genannten Exceptions, welche sich auch aus der Funktion heraus leiten lassen.
Das war es erst einmal.
Zu den gestern schon angesprochenen Modulen und Codes verrate ich auch schon einmal etwas:
Die Probleme, ein Ziel zu treffen, sollten hiermit ein Ende haben.
Bis zum nächsten Eintrag!
mpmxyz
ein Schritt zurück und ein Sprung vorwärts
Ich hatte in den Ferien nicht an meinen Tokenizer weiter arbeiten können. (Ich hatte den Code nicht mitgenommen gehabt. -.-)
Die Auszeit hat mir aber die Gelegenheit gegeben, das Projekt zu überdenken.
Dabei ist mir aufgefallen, dass ich mit dem Projekt relativ unzufrieden bin.
Daher werde werde erst einmal wieder bei den Token neu anfangen.
Deren Funktionen wurden auf das Notwendigste reduziert; das Mini-Script fiel heraus und es verschwanden mir zu unflexible Klassen.
Dafür wurde ein sehr simples, aber mehr als ausreichendes Metadaten-System eingeführt. (Strings werden Objekte zugeordnet. )
)
Nun die wichtigste Nachricht:
Der Parser ist jetzt sehr flexibel und erweiterbar.
Ich habe mich dabei von diesem schönen Tutorial inspirieren lassen:
http://dev.xscheme.de/2009/07/...iptsprach/ (genauer: Ansatz 4 für den Lexer)
Kurz formuliert kann man den Algorithmus als eine Art Wettrennen bezeichnen:
Dabei treten die ganzen Token-Möglichkeiten gegeneinander an. (im Modul "TCodeRacer")
Normalerweise "gewinnt" dabei die Möglichkeit, die als letztes "aufgegeben" hat.
Falls diese aber feststellt, dass sie unvollständig oder fehlerhaft ist, werden die Möglichkeiten, die bei kürzeren Token möglich wären, getestet. (Der rein theoretische Worst Case wäre O(n^2*m). In der Praxis liegt man eher bei O(n) bis O(n*m). (n=Codelänge, m=Anzahl an "Wettfahrern"))
Die Zeit in den Ferien habe ich übrigens produktiv genutzt:
Wenn ich den Tokenizer veröffentlichen werde, werde ich zusätzlich mindestens 9 weitere Module und einige Codes zu Tage befördern.
Bis irgendwann!
mpmxyz
Die Auszeit hat mir aber die Gelegenheit gegeben, das Projekt zu überdenken.
Dabei ist mir aufgefallen, dass ich mit dem Projekt relativ unzufrieden bin.
Daher werde werde erst einmal wieder bei den Token neu anfangen.
Deren Funktionen wurden auf das Notwendigste reduziert; das Mini-Script fiel heraus und es verschwanden mir zu unflexible Klassen.
Dafür wurde ein sehr simples, aber mehr als ausreichendes Metadaten-System eingeführt. (Strings werden Objekte zugeordnet.
Nun die wichtigste Nachricht:
Der Parser ist jetzt sehr flexibel und erweiterbar.
Ich habe mich dabei von diesem schönen Tutorial inspirieren lassen:
http://dev.xscheme.de/2009/07/...iptsprach/ (genauer: Ansatz 4 für den Lexer)
Kurz formuliert kann man den Algorithmus als eine Art Wettrennen bezeichnen:
Dabei treten die ganzen Token-Möglichkeiten gegeneinander an. (im Modul "TCodeRacer")
Normalerweise "gewinnt" dabei die Möglichkeit, die als letztes "aufgegeben" hat.
Falls diese aber feststellt, dass sie unvollständig oder fehlerhaft ist, werden die Möglichkeiten, die bei kürzeren Token möglich wären, getestet. (Der rein theoretische Worst Case wäre O(n^2*m). In der Praxis liegt man eher bei O(n) bis O(n*m). (n=Codelänge, m=Anzahl an "Wettfahrern"))
Die Zeit in den Ferien habe ich übrigens produktiv genutzt:
Wenn ich den Tokenizer veröffentlichen werde, werde ich zusätzlich mindestens 9 weitere Module und einige Codes zu Tage befördern.
Bis irgendwann!
mpmxyz
Das Ergebnis des If-Spiels: 2 zu 0 für den Tokenizer
Bevor ich mich um den Inhalt kümmere, bitte ich um eine Schweigeminute:
Ab diesen Tag gibt es zwei Fliegen weniger in dieser Welt.
Eine hungrige Sarracenia hatte sie zum Fressen gern.
Ich habe mich in der letzten Zeit immer wieder mal mit dem Tokenizer beschäftigt.
Irgendwann dachte ich, dass ich am Ende angekommen bin, und traf dann auf das hier:
BlitzMax: [AUSKLAPPEN]
Daraus wird endlich das hier:
Code: [AUSKLAPPEN]
Wer den Token-Code ausführlich betrachtet findet außerdem eine weitere Neuerung:
Angaben, die aus mehreren mit Kommas getrennten Teilen bestehen, werden in ihre einzelnen "Dimensionen" strukturiert. (Local-, Global-, Const- und Field-Deklarationen, Case-"Vorschläge" und Eingeklammertes)
Ich arbeite daran, die Strukturierung einstellbar zu machen. (Sollen Klammern strukturiert werden? Was ist mit Deklarationen? ...)
Ein Ziel, welches ich für den Tokenizer habe, wurde hier noch nicht genannt:
Das, was er mit mehreren ParseLine-Aufrufen einliest, soll 1 zu 1 wieder bei "toCode" herauskommen.
Im Moment klappt das trotz der Struktur ganz einfach.
Für diejenigen, die Zahlen mögen, habe ich auch etwas:
Code: [AUSKLAPPEN]
Damit ich den letzten Punkt garantieren kann, bitte ich euch, kleine Testcodes mit allen möglichen Schikanen und Strukturtests auszudenken.
Als Beispiel kann zum Beispiel dies hier dienen:
BlitzMax: [AUSKLAPPEN]
Dieser Code wird zu dieser Struktur umgewandelt:
Code: [AUSKLAPPEN]
Ich danke schon einmal für die Debug-Hilfe!
Ich wünsche auch weiterhin schöne Tage mit entsprechenden Wetter!
mpmxyz
Ab diesen Tag gibt es zwei Fliegen weniger in dieser Welt.
Eine hungrige Sarracenia hatte sie zum Fressen gern.
Ich habe mich in der letzten Zeit immer wieder mal mit dem Tokenizer beschäftigt.
Irgendwann dachte ich, dass ich am Ende angekommen bin, und traf dann auf das hier:
BlitzMax: [AUSKLAPPEN]
SuperStrict
Local a:Int=1,b:Int=2
If a If b
Print "1"
EndIf
If a While b
Print b
b:-1
Wend
If a If b Print "2";Print "3"
Daraus wird endlich das hier:
Code: [AUSKLAPPEN]
Program: "If-Test2.bmx"
Identifier: "SuperStrict"
NewLine: ""
Identifier: "Local"
: ""
Space: " "
Letter: "a"
: ":"
Identifier: "Int"
: "="
Dec: "1"
: ","
Letter: "b"
: ":"
Identifier: "Int"
: "="
Dec: "2"
NewLine: ""
Identifier: "If"
Space: " "
Letter: "a"
Space: " "
Identifier: "If"
Space: " "
Letter: "b"
NewLine: ""
Space: " "
Letter: "Print"
Space: " "
String: "1"
NewLine: ""
Identifier: "EndIf"
NewLine: ""
Identifier: "If"
Space: " "
Letter: "a"
Space: " "
Identifier: "While"
Space: " "
Letter: "b"
NewLine: ""
Space: " "
Letter: "Print"
Space: " "
Letter: "b"
NewLine: ""
Space: " "
Letter: "b"
: ":-"
Dec: "1"
NewLine: ""
Identifier: "Wend"
NewLine: ""
Identifier: "If"
Space: " "
Letter: "a"
Space: " "
Identifier: "If"
Space: " "
Letter: "b"
Space: " "
Letter: "Print"
Space: " "
String: "2"
: ";"
Letter: "Print"
Space: " "
String: "3"
NewLine: ""
NewLine: ""
Identifier: "SuperStrict"
NewLine: ""
Identifier: "Local"
: ""
Space: " "
Letter: "a"
: ":"
Identifier: "Int"
: "="
Dec: "1"
: ","
Letter: "b"
: ":"
Identifier: "Int"
: "="
Dec: "2"
NewLine: ""
Identifier: "If"
Space: " "
Letter: "a"
Space: " "
Identifier: "If"
Space: " "
Letter: "b"
NewLine: ""
Space: " "
Letter: "Print"
Space: " "
String: "1"
NewLine: ""
Identifier: "EndIf"
NewLine: ""
Identifier: "If"
Space: " "
Letter: "a"
Space: " "
Identifier: "While"
Space: " "
Letter: "b"
NewLine: ""
Space: " "
Letter: "Print"
Space: " "
Letter: "b"
NewLine: ""
Space: " "
Letter: "b"
: ":-"
Dec: "1"
NewLine: ""
Identifier: "Wend"
NewLine: ""
Identifier: "If"
Space: " "
Letter: "a"
Space: " "
Identifier: "If"
Space: " "
Letter: "b"
Space: " "
Letter: "Print"
Space: " "
String: "2"
: ";"
Letter: "Print"
Space: " "
String: "3"
NewLine: ""
NewLine: ""
Wer den Token-Code ausführlich betrachtet findet außerdem eine weitere Neuerung:
Angaben, die aus mehreren mit Kommas getrennten Teilen bestehen, werden in ihre einzelnen "Dimensionen" strukturiert. (Local-, Global-, Const- und Field-Deklarationen, Case-"Vorschläge" und Eingeklammertes)
Ich arbeite daran, die Strukturierung einstellbar zu machen. (Sollen Klammern strukturiert werden? Was ist mit Deklarationen? ...)
Ein Ziel, welches ich für den Tokenizer habe, wurde hier noch nicht genannt:
Das, was er mit mehreren ParseLine-Aufrufen einliest, soll 1 zu 1 wieder bei "toCode" herauskommen.
Im Moment klappt das trotz der Struktur ganz einfach.
Für diejenigen, die Zahlen mögen, habe ich auch etwas:
Code: [AUSKLAPPEN]
Zeilen: 999
Zeichen: 27.182
Token: 7.155
Einlesezeit mit Strukturierung: 167 ms
Fehler in der Strukturierung: 0
Zeichen: 27.182
Token: 7.155
Einlesezeit mit Strukturierung: 167 ms
Fehler in der Strukturierung: 0
Damit ich den letzten Punkt garantieren kann, bitte ich euch, kleine Testcodes mit allen möglichen Schikanen und Strukturtests auszudenken.
Als Beispiel kann zum Beispiel dies hier dienen:
BlitzMax: [AUSKLAPPEN]
SuperStrict
Type T{a=2}
Method A:Int(p1:Int,t2:Test)
Local c:Int,d:Float
For Local i2:Int=c Until 100
Print (i2)+2
Next
Function f(a1:Byte,a2:Byte,a3:Byte(t:Int,u:Int,v:Object[]))
EndFunction
EndMethod
EndType
Dieser Code wird zu dieser Struktur umgewandelt:
Code: [AUSKLAPPEN]
Program: "Komma-Test.bmx"
Identifier: "SuperStrict"
NewLine: ""
Identifier: "Type"
Space: " "
Letter: "T"
: "{"
: ""
Letter: "a"
: "="
Dec: "2"
: "}"
NewLine: ""
Space: " "
Identifier: "Method"
Space: " "
Letter: "A"
: ":"
Identifier: "Int"
: "("
: ""
Letter: "p1"
: ":"
Identifier: "Int"
: ","
Letter: "t2"
: ":"
Letter: "Test"
: ")"
NewLine: ""
Space: " "
Identifier: "Local"
: ""
Space: " "
Letter: "c"
: ":"
Identifier: "Int"
: ","
Letter: "d"
: ":"
Identifier: "Float"
NewLine: ""
Space: " "
Identifier: "For"
Space: " "
Identifier: "Local"
: ""
Space: " "
Letter: "i2"
: ":"
Identifier: "Int"
: "="
Letter: "c"
Space: " "
Identifier: "Until"
Space: " "
Dec: "100"
NewLine: ""
Space: " "
Letter: "Print"
Space: " "
: "("
: ""
Letter: "i2"
: ")"
: "+"
Dec: "2"
NewLine: ""
Space: " "
Identifier: "Next"
NewLine: ""
Space: " "
Identifier: "Function"
Space: " "
Letter: "f"
: "("
: ""
Letter: "a1"
: ":"
Identifier: "Byte"
: ","
Letter: "a2"
: ":"
Identifier: "Byte"
: ","
Letter: "a3"
: ":"
Identifier: "Byte"
: "("
: ""
Letter: "t"
: ":"
Identifier: "Int"
: ","
Letter: "u"
: ":"
Identifier: "Int"
: ","
Letter: "v"
: ":"
Identifier: "Object"
: "["
: ""
: "]"
: ")"
: ")"
NewLine: ""
Space: " "
NewLine: ""
Space: " "
Identifier: "EndFunction"
NewLine: ""
Space: " "
Identifier: "EndMethod"
NewLine: ""
Identifier: "EndType"
NewLine: ""
Identifier: "SuperStrict"
NewLine: ""
Identifier: "Type"
Space: " "
Letter: "T"
: "{"
: ""
Letter: "a"
: "="
Dec: "2"
: "}"
NewLine: ""
Space: " "
Identifier: "Method"
Space: " "
Letter: "A"
: ":"
Identifier: "Int"
: "("
: ""
Letter: "p1"
: ":"
Identifier: "Int"
: ","
Letter: "t2"
: ":"
Letter: "Test"
: ")"
NewLine: ""
Space: " "
Identifier: "Local"
: ""
Space: " "
Letter: "c"
: ":"
Identifier: "Int"
: ","
Letter: "d"
: ":"
Identifier: "Float"
NewLine: ""
Space: " "
Identifier: "For"
Space: " "
Identifier: "Local"
: ""
Space: " "
Letter: "i2"
: ":"
Identifier: "Int"
: "="
Letter: "c"
Space: " "
Identifier: "Until"
Space: " "
Dec: "100"
NewLine: ""
Space: " "
Letter: "Print"
Space: " "
: "("
: ""
Letter: "i2"
: ")"
: "+"
Dec: "2"
NewLine: ""
Space: " "
Identifier: "Next"
NewLine: ""
Space: " "
Identifier: "Function"
Space: " "
Letter: "f"
: "("
: ""
Letter: "a1"
: ":"
Identifier: "Byte"
: ","
Letter: "a2"
: ":"
Identifier: "Byte"
: ","
Letter: "a3"
: ":"
Identifier: "Byte"
: "("
: ""
Letter: "t"
: ":"
Identifier: "Int"
: ","
Letter: "u"
: ":"
Identifier: "Int"
: ","
Letter: "v"
: ":"
Identifier: "Object"
: "["
: ""
: "]"
: ")"
: ")"
NewLine: ""
Space: " "
NewLine: ""
Space: " "
Identifier: "EndFunction"
NewLine: ""
Space: " "
Identifier: "EndMethod"
NewLine: ""
Identifier: "EndType"
NewLine: ""
Ich danke schon einmal für die Debug-Hilfe!
Ich wünsche auch weiterhin schöne Tage mit entsprechenden Wetter!
mpmxyz
Etwas strukturierter bitte!
Das gröbste ist überstanden.
Mein Kopf raucht nicht mehr.
Zum Glück gibt es gegen die Abwärme ein f.e.n.s.t.E.R. *
Da kommen zum Beispiel Fliegen herein.
Die kann man schlagen, mit der Pinzette anheben, herunterfallen lassen, kleben, in Fallen setzen, wieder kleben, herunterfallen lassen, schlagen, mit der Pinzette nehmen und an Pflanzen verfüttern.
Ok, das sollte jetzt meine Beschäftigung in meinem Zimmerchen ausgiebig beschreiben.
Nein, ich bin nicht verrückt, ich bin einfach nur froh, dass ich diesen Teil (fast) hinter mir habe.
Warum?
If!
IF!
BlitzMax: [AUSKLAPPEN]
Ein EndIf oder kein EndIf? Das ist hier die Frage!
Mein Tokenizer könnte sie beantworten:
"Nein!"
Bei der oben und unten angesprochenen Struktur geht es zum Beispiel darum:
BlitzMax: [AUSKLAPPEN]
>>TBMXToken.GenerateTree()>>
Code: [AUSKLAPPEN]
Diese ist eigentlich einfach zu erstellen:
Es gibt Token, die eine Ebene tiefer führen, und es gibt Token, die eine Ebene zurück führen.
Nun kommt aber das für den Anwender sehr angenehme If ins Spiel:
Zitat:
So oder ähnlich steht es in den Tutorials.
Doch wenn man dieses Verhalten ohne Unterschied nachahmen möchte und nicht gerade den BlitzMax-Compiler-Code zur Hand hat, muss man eine Menge herumprobieren - und denken; immerhin sollte man die Eigenschaften von BlitzMax gezielt untersuchen.
Das alles hat mir einige Stunden Beschäftigung bereitet, zumal ich zwischendurch erst einmal feststellen musste, dass BlitzMax keine Fehler meldet, wenn es Module kompiliert.
Jetzt muss ich nur noch einzeilige Ifs zu einer Struktur machen und dann geht es darum, die neue Struktur zu bearbeiten.
Immerhin soll man bei Funktionsaufrufen auch mehr als nur einen Parameter nutzen können.
Danach bringe ich dem Parser wahrscheinlich etwas Mathematik bei.
Zur Vollendung bleiben dann noch Methoden, die Funktionen, Methoden und Variablen identifizieren.
Irgendwann muss ich mir noch einmal überlegen, was ich mit diesem Worklog wirklich erreichen möchte.
Zwei oder drei der weiter unten stehenden Punkte haben sich nämlich meiner Meinung nach erübrigt.
Bis ich mit das überlegt habe, wünsche ich euch schöne Tage!
mpmxyz
P.S.: Hier braut sich einiges an Code zusammen... Den möchte ich aber erst einmal schön "verpacken", bevor ich etwas dazu sage.
*) feines, extrem neuartiges und supertolles Etwas mit Rolladen
Mein Kopf raucht nicht mehr.
Zum Glück gibt es gegen die Abwärme ein f.e.n.s.t.E.R. *
Da kommen zum Beispiel Fliegen herein.
Die kann man schlagen, mit der Pinzette anheben, herunterfallen lassen, kleben, in Fallen setzen, wieder kleben, herunterfallen lassen, schlagen, mit der Pinzette nehmen und an Pflanzen verfüttern.
Ok, das sollte jetzt meine Beschäftigung in meinem Zimmerchen ausgiebig beschreiben.
Nein, ich bin nicht verrückt, ich bin einfach nur froh, dass ich diesen Teil (fast) hinter mir habe.
Warum?
If!
IF!
BlitzMax: [AUSKLAPPEN]
If a.. 'b
Rem
c
EndRem
=d..
Rem
a EndRem
e
EndRem
Rem
f
EndRem
Print "g"
Ein EndIf oder kein EndIf? Das ist hier die Frage!
Mein Tokenizer könnte sie beantworten:
"Nein!"
Bei der oben und unten angesprochenen Struktur geht es zum Beispiel darum:
BlitzMax: [AUSKLAPPEN]
While a(b[c+1])
Print "1"
Wend
>>TBMXToken.GenerateTree()>>
Code: [AUSKLAPPEN]
Program: "If-Test.bmx" (Line: 0,File: "")
Identifier: "While" (Line: 1,File: "If-Test.bmx")
Space: " " (Line: 1,File: "If-Test.bmx")
Letter: "a" (Line: 1,File: "If-Test.bmx")
: "(" (Line: 1,File: "If-Test.bmx")
Letter: "b" (Line: 1,File: "If-Test.bmx")
: "[" (Line: 1,File: "If-Test.bmx")
Letter: "c" (Line: 1,File: "If-Test.bmx")
: "+" (Line: 1,File: "If-Test.bmx")
Dec: "1" (Line: 1,File: "If-Test.bmx")
: "]" (Line: 1,File: "If-Test.bmx")
: ")" (Line: 1,File: "If-Test.bmx")
NewLine: "" (Line: 1,File: "If-Test.bmx")
Space: " " (Line: 2,File: "If-Test.bmx")
Letter: "Print" (Line: 2,File: "If-Test.bmx")
Space: " " (Line: 2,File: "If-Test.bmx")
String: "1" (Line: 2,File: "If-Test.bmx")
NewLine: "" (Line: 2,File: "If-Test.bmx")
Identifier: "Wend" (Line: 3,File: "If-Test.bmx")
Identifier: "While" (Line: 1,File: "If-Test.bmx")
Space: " " (Line: 1,File: "If-Test.bmx")
Letter: "a" (Line: 1,File: "If-Test.bmx")
: "(" (Line: 1,File: "If-Test.bmx")
Letter: "b" (Line: 1,File: "If-Test.bmx")
: "[" (Line: 1,File: "If-Test.bmx")
Letter: "c" (Line: 1,File: "If-Test.bmx")
: "+" (Line: 1,File: "If-Test.bmx")
Dec: "1" (Line: 1,File: "If-Test.bmx")
: "]" (Line: 1,File: "If-Test.bmx")
: ")" (Line: 1,File: "If-Test.bmx")
NewLine: "" (Line: 1,File: "If-Test.bmx")
Space: " " (Line: 2,File: "If-Test.bmx")
Letter: "Print" (Line: 2,File: "If-Test.bmx")
Space: " " (Line: 2,File: "If-Test.bmx")
String: "1" (Line: 2,File: "If-Test.bmx")
NewLine: "" (Line: 2,File: "If-Test.bmx")
Identifier: "Wend" (Line: 3,File: "If-Test.bmx")
Diese ist eigentlich einfach zu erstellen:
Es gibt Token, die eine Ebene tiefer führen, und es gibt Token, die eine Ebene zurück führen.
Nun kommt aber das für den Anwender sehr angenehme If ins Spiel:
Zitat:
Es gibt zwei Formen von If. Die eine ist einzeilig und die andere geht über mehrere Zeilen. Das 'Then' kann weggelassen werden.
So oder ähnlich steht es in den Tutorials.
Doch wenn man dieses Verhalten ohne Unterschied nachahmen möchte und nicht gerade den BlitzMax-Compiler-Code zur Hand hat, muss man eine Menge herumprobieren - und denken; immerhin sollte man die Eigenschaften von BlitzMax gezielt untersuchen.
Das alles hat mir einige Stunden Beschäftigung bereitet, zumal ich zwischendurch erst einmal feststellen musste, dass BlitzMax keine Fehler meldet, wenn es Module kompiliert.
Jetzt muss ich nur noch einzeilige Ifs zu einer Struktur machen und dann geht es darum, die neue Struktur zu bearbeiten.
Immerhin soll man bei Funktionsaufrufen auch mehr als nur einen Parameter nutzen können.
Danach bringe ich dem Parser wahrscheinlich etwas Mathematik bei.
Zur Vollendung bleiben dann noch Methoden, die Funktionen, Methoden und Variablen identifizieren.
Irgendwann muss ich mir noch einmal überlegen, was ich mit diesem Worklog wirklich erreichen möchte.
Zwei oder drei der weiter unten stehenden Punkte haben sich nämlich meiner Meinung nach erübrigt.
Bis ich mit das überlegt habe, wünsche ich euch schöne Tage!
mpmxyz
P.S.: Hier braut sich einiges an Code zusammen... Den möchte ich aber erst einmal schön "verpacken", bevor ich etwas dazu sage.
*) feines, extrem neuartiges und supertolles Etwas mit Rolladen
Stille
In der letzten Zeit war es ziemlich Still in diesem Worklog.
Böse Zungen hätten sogar das Recht gehabt, dass sich gar nichts tut.
Das war in einigen Wochen wirklich der Fall gewesen.
Aber trotzdem hat sich einiges getan:
bis zum nächsten Eintrag
mpmxyz
Böse Zungen hätten sogar das Recht gehabt, dass sich gar nichts tut.
Das war in einigen Wochen wirklich der Fall gewesen.
Aber trotzdem hat sich einiges getan:
- Der TToken-Type ist fertig.
Das System der regulären Token-Ausdrücke ist zwar fertig, aber es ist relativ lahm.
Mit einer Modifikation des brl.LinkedList-Moduls habe ich die Geschwindigkeit aber immerhin verzehnfachen können. - Von diesem Type ist ein weiterer abgeleitet, der für Programm-Code zuständig ist: Der TCodeToken-Type
Er hat folgende Methoden:- ParseLine wandelt eine Codezeile in Token um.
- ToCode macht genau das umgekehrte.
- ParseLine wandelt eine Codezeile in Token um.
- Ich habe den von dem TCodeToken-Type erbenden TBMXToken-Type erstellt.
Folgendes wird alles schon erkannt:- Strings
- Zahlen und deren Schreibweise (hexadezimal, als Float...)
- Die Standard-Identifier, wie Local
 , Global und Function (Es wird sogar die getrennte Schreibweise erkannt.)
, Global und Function (Es wird sogar die getrennte Schreibweise erkannt.)
- und Kommentare
- Strings
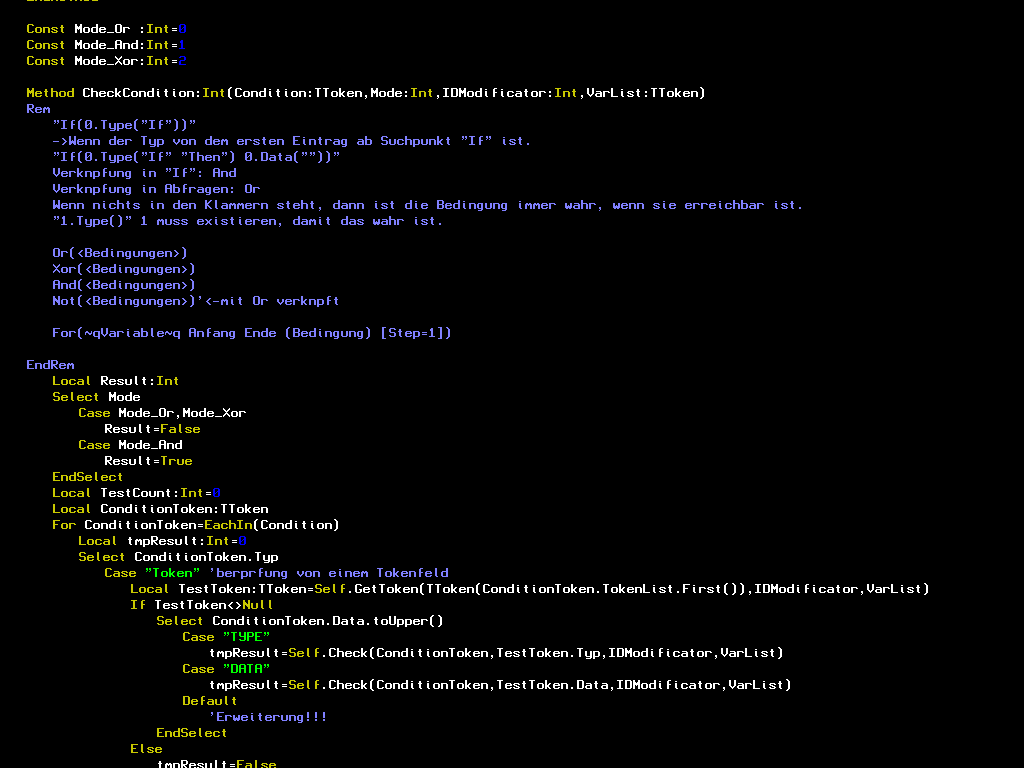
- Ich habe mich am Syntax-Highlighting versucht:
(Man schaue auf die hervorgehobenen Zahlen!)
Die 28 Kilobytes Code wurden in 100 ms geladen und werden flüssig mit einer frei einstellbaren Einrücktiefe angezeigt; es gibt zusätzlich gewaltige Optimierungsmöglichkeiten. - Ich bin dabei, einen eigenen Code-Cruncher zu schreiben.
Seine Ausgabe beim Crunchen des eigenen Codes sieht so aus:
Code: [AUSKLAPPEN]Input: 4935 Bytes
Output: 3359 Bytes
Das wird demnächst aber ein besseres Ergebnis, da ich auch die Variablen-/Type-/Funktionsnamen auf ein Minimum komprimieren möchte.
Außerdem werde ich versuchen, auch das letzte unnötige Leerzeichen zu eleminieren.
bis zum nächsten Eintrag
mpmxyz
Am Anfang waren die Token...
Nachdem ich nun genug - bis in die tiefe Nacht - mit meinem Weihnachtsgeschenk gespielt habe, setzte ich mich mal an meinen Worklog.
In diesem Eintrag geht es - unschwer am Titel erkennbar - um das Token-System, welches ein zentraler Bestandteil des Tokenizers ist.
Auch, wenn man mit den Token vieles anstellen kann, hat jeder von ihnen nur 3 1/2 Eigenschaften:
Und damit kann man schon alle Code-Strukturen darstellen:
BlitzMax: [AUSKLAPPEN]
könnte so zu dem nachfolgenden Token-Baum werden:
Code: [AUSKLAPPEN]
Anmerkung: Es gibt gewisse Grammatik-Regeln in BlitzMax, bei denen Leerzeichen beachtet werden müssen.
Wenn man außerdem einen Precompiler schreibt, kann es von Vorteil sein, dass die Formatierung des bearbeiteten Codes erhalten bleibt.
Komplexere Strukturen lassen sich mit diesem System ähnlich erstellen; für ein Beispiel fehlt mir aber im Moment eine genauer Plan in diese Richtung.
Erst einmal muss ich nämlich die regulären Ausdrücke weiter entwickeln.
Das war erst einmal alles, was ich zu den Token an sich sagen wollte.
Wie die Token angewendet werden, wird dann in weiteren Einträgen bearbeitet.
bis zum nächsten Eintrag
mpmxyz
In diesem Eintrag geht es - unschwer am Titel erkennbar - um das Token-System, welches ein zentraler Bestandteil des Tokenizers ist.
Auch, wenn man mit den Token vieles anstellen kann, hat jeder von ihnen nur 3 1/2 Eigenschaften:
- einen Typ (ein String)
- einen Datenblock (auch ein String)
- ein Parent bzw. einen Ober-Token und eine beliebige Anzahl an Childs bzw. Unter-Token
Und damit kann man schon alle Code-Strukturen darstellen:
BlitzMax: [AUSKLAPPEN]
If a=b Then c=d Else d=c 'Das ist ein Test.
könnte so zu dem nachfolgenden Token-Baum werden:
Code: [AUSKLAPPEN]
File: "irgendetwas.bmx"
Line: "1"
If: ""
Condition: ""
Space: " "
Operator: "="
Variable: "a"
Variable: "b"
Space: " "
Then: ""
Space: " "
Assignment: "="
Variable: ""
Variable: "c"
Expression: ""
Variable: "d"
Space: " "
Else: ""
Space: " "
Assignment: "="
Variable: ""
Variable: "d"
Expression: ""
Variable: "c"
Space: " "
Comment: "Das ist ein Test."
Line: "1"
If: ""
Condition: ""
Space: " "
Operator: "="
Variable: "a"
Variable: "b"
Space: " "
Then: ""
Space: " "
Assignment: "="
Variable: ""
Variable: "c"
Expression: ""
Variable: "d"
Space: " "
Else: ""
Space: " "
Assignment: "="
Variable: ""
Variable: "d"
Expression: ""
Variable: "c"
Space: " "
Comment: "Das ist ein Test."
Anmerkung: Es gibt gewisse Grammatik-Regeln in BlitzMax, bei denen Leerzeichen beachtet werden müssen.
Wenn man außerdem einen Precompiler schreibt, kann es von Vorteil sein, dass die Formatierung des bearbeiteten Codes erhalten bleibt.
Komplexere Strukturen lassen sich mit diesem System ähnlich erstellen; für ein Beispiel fehlt mir aber im Moment eine genauer Plan in diese Richtung.
Erst einmal muss ich nämlich die regulären Ausdrücke weiter entwickeln.
Das war erst einmal alles, was ich zu den Token an sich sagen wollte.
Wie die Token angewendet werden, wird dann in weiteren Einträgen bearbeitet.
bis zum nächsten Eintrag
mpmxyz
Immer diese Fragen...
Was wird das für ein Projekt?
Zuerst werde ich mich in diesem Worklog einem Tokenizer für BlitzMax, an dem ich seit dem 19.12 arbeite, widmen
Da so ein Tokenizer sehr nützlich sein kann, könnten aber auch noch schnell weitere, mehr oder weniger kleine Projekte, die aus dem Tokenizer entstanden sind, hinzukommen.
Man könnte z.B. auf Basis dieses Tokenizers eine BlitzMax-IDE erstellen, BlitzMax-Code interpretieren oder übersetzen.
(Mit Übersetzen meine ich übrigens eher etwas, wie einen Precompiler.)
Was ist das Besondere an diesem Projekt?
Ich versuche, den Tokenizer so flexibel wie nur möglich zu gestalten, damit es für ihn möglichst viele Anwendungsmöglichkeiten gibt.
So habe ich z.B. in einer halben Stunde einen kleinen Precompiler erstellen können, der Code verkleinern kann:
Der Precompilercode wurde von 29 KiB um mehr als 27% auf 21 KiB verkleinert!
Um diese Einfachheit zu erhalten, habe ich eine sehr simple, aber auch extrem mächtige Art regulärer Ausdrücke für Token entwickelt.
Damit lassen sich sogar viele Verhaltensweisen des Tokenizers zu Laufzeit ändern!
Selbst diese regulären Ausdrücke werden in Token zerlegt und können genau so bearbeitet werden, wie BlitzMax-Code.
Und die Token können noch mehr:
Die Kombination aus einem regulären Ausdruck und einer dazugehörigen „Ausgabe“ kann in einem Regel-Token gespeichert werden, welcher wiederum mit Hilfe von weiteren Token in einer Gruppe von Regeln gesteckt werden kann.
Alle Regeln/Regelgruppen können dann über DEN Ober-Token verknüpft werden, um in einem einfachen Befehl verwendet zu werden.
Was wird es zu hören/sehen geben?
-Ich werde versuchen, bis ins kleinste Detail die Regeln zum Parsen von BlitzMax-Code zu erklären.
-Sobald ich mit den Grundlagen davon fertig bin, werde ich die Syntax meiner Art von regulären Ausdrücken erklären und mit dem ersten Punkt weiter machen.
-Das, was ich mit dem Tokenizer so mache, kommt auch ab und zu hier herein.
-Wenn ich den Code genug dokumentiert habe, kommt er auch hier herein, weil mir die Möglichkeiten des Projekts sonst zu Schade dafür sind, dass er nur auf meiner Festplatte liegt.
-Wenn jemand eine nützliche Regel/Regelgruppe gefunden hat, kann diese auch dann auch hier auftauchen.
Das Erste, was ich erklären werde, sind die Token selbst.
Um hier allerdings alles übersichtlich zu halten, wird das erst im nächsten Eintrag stehen.
bis zum nächsten Eintrag
mpmxyz
Zuerst werde ich mich in diesem Worklog einem Tokenizer für BlitzMax, an dem ich seit dem 19.12 arbeite, widmen
Da so ein Tokenizer sehr nützlich sein kann, könnten aber auch noch schnell weitere, mehr oder weniger kleine Projekte, die aus dem Tokenizer entstanden sind, hinzukommen.
Man könnte z.B. auf Basis dieses Tokenizers eine BlitzMax-IDE erstellen, BlitzMax-Code interpretieren oder übersetzen.
(Mit Übersetzen meine ich übrigens eher etwas, wie einen Precompiler.)
Was ist das Besondere an diesem Projekt?
Ich versuche, den Tokenizer so flexibel wie nur möglich zu gestalten, damit es für ihn möglichst viele Anwendungsmöglichkeiten gibt.
So habe ich z.B. in einer halben Stunde einen kleinen Precompiler erstellen können, der Code verkleinern kann:
Der Precompilercode wurde von 29 KiB um mehr als 27% auf 21 KiB verkleinert!
Um diese Einfachheit zu erhalten, habe ich eine sehr simple, aber auch extrem mächtige Art regulärer Ausdrücke für Token entwickelt.
Damit lassen sich sogar viele Verhaltensweisen des Tokenizers zu Laufzeit ändern!
Selbst diese regulären Ausdrücke werden in Token zerlegt und können genau so bearbeitet werden, wie BlitzMax-Code.
Und die Token können noch mehr:
Die Kombination aus einem regulären Ausdruck und einer dazugehörigen „Ausgabe“ kann in einem Regel-Token gespeichert werden, welcher wiederum mit Hilfe von weiteren Token in einer Gruppe von Regeln gesteckt werden kann.
Alle Regeln/Regelgruppen können dann über DEN Ober-Token verknüpft werden, um in einem einfachen Befehl verwendet zu werden.
Was wird es zu hören/sehen geben?
-Ich werde versuchen, bis ins kleinste Detail die Regeln zum Parsen von BlitzMax-Code zu erklären.
-Sobald ich mit den Grundlagen davon fertig bin, werde ich die Syntax meiner Art von regulären Ausdrücken erklären und mit dem ersten Punkt weiter machen.
-Das, was ich mit dem Tokenizer so mache, kommt auch ab und zu hier herein.
-Wenn ich den Code genug dokumentiert habe, kommt er auch hier herein, weil mir die Möglichkeiten des Projekts sonst zu Schade dafür sind, dass er nur auf meiner Festplatte liegt.
-Wenn jemand eine nützliche Regel/Regelgruppe gefunden hat, kann diese auch dann auch hier auftauchen.
Das Erste, was ich erklären werde, sind die Token selbst.
Um hier allerdings alles übersichtlich zu halten, wird das erst im nächsten Eintrag stehen.
bis zum nächsten Eintrag
mpmxyz