Problem mit Tlist im Type
Übersicht

SchrolliBetreff: Problem mit Tlist im Type |
Antworten mit Zitat |
|
|---|---|---|
|
Habe ein Problem mit der Benutzung von Tlist in einem Type
Follgende Ausgabe: Code: [AUSKLAPPEN] Executing:untitled1.exe
New TTileEngine created New TTileLayer created: Test Layer1 New TTileLayer created: Test Layer2 New TTileLayer created: Test Layer3 exit Komischerweise hat die Liste wie im Code zu erwarten 3 Einträge. Die in name gespeicherten Strings sind aber weg. Was läuft denn hier schief? BlitzMax: [AUSKLAPPEN]
Grüße |
||

|
Midimaster |
Antworten mit Zitat |
|---|---|---|
|
Du mischt da was....
Auf der einene Seite hast Du in der Methode "TTileEngine-Create" die lokale variable CONSTRUCTOR erstellt, die Du auch zurückgibts. Aber die Werte weist Du SELF zu. Dies geht sogar schon beim Wert WINDOWX schief: teste dies: BlitzMax: [AUSKLAPPEN] SuperStrict Meiner Meinung nach müßte die "TTileEngine-Create" so aussehen: BlitzMax: [AUSKLAPPEN] 'Constructor das gleiche dann auch bei "TTileLayer Method Create": BlitzMax: [AUSKLAPPEN] Type TTileLayer Die Namensgleichheit bei den zu übergebenden Parametern und dem Type selbst kann übrigens zu Problemen führen. Besser so: BlitzMax: [AUSKLAPPEN] Method Create:TTileLayer(N:String) Dann ginge es nämlich auch so: BlitzMax: [AUSKLAPPEN] SuperStrict und so auch: BlitzMax: [AUSKLAPPEN] SuperStrict |
||
| Gewinner des BCC #53 mit "Gitarrist vs Fussballer" http://www.midimaster.de/downl...ssball.exe | ||
- Zuletzt bearbeitet von Midimaster am Di, Jan 26, 2016 9:45, insgesamt einmal bearbeitet
Schrolli |
Antworten mit Zitat |
|
|---|---|---|
|
Danke, das wars tatsächlich...
Was ich aber nicht ganz verstehe - normalerweise nutzt man self ja, um sich selbst die werte zuzuweisen. nach dem "new TTileEngine" wird ja ein neues Objekt erstellt, wieso kann er in diesem Fall die Werte nicht per self an sich selbst übergeben? Grüße Basti |
||
|
|
Midimaster |
Antworten mit Zitat |
|---|---|---|
| ich habe meinen Text oben gerade nochmal um genau dieses Thema ergänzt, da hattest Du aber schon in der Zwischenzeit schnell geantwortet.... Schau Dir das oben jetzt bitte nochmal an. | ||
| Gewinner des BCC #53 mit "Gitarrist vs Fussballer" http://www.midimaster.de/downl...ssball.exe | ||
Schrolli |
Antworten mit Zitat |
|
|---|---|---|
|
Ahhh jetzt versteh ich das glaube ich...
Das mit den gleichen Namen habe ich mir mal so angewöhnt, da man mir sagte es sei nicht unbedingt schlechter Code Stil, wenn das Zeug ordentlich und zuordenbar heißt. Auf alle Variablen innerhalb der Klasse wird dann strikt per self zugegriffen, dann kann das auch nicht zu Verwechslungen kommen. Habs jetzt in Anlehnung an dein Beispiel so gelöst, läuft super BlitzBasic: [AUSKLAPPEN]
Edit: Kann ich in der Liste auf einzelne Elemente eigentlich irgendwie per ID zugreifen, ähnlich wie bei nem Array? Oder gibt es einen anderen Datentyp der so etwas gut beherrscht? Brauche im Prinzip etwas, wie ein Array, dessen Größe ich aber variabel zur Laufzeit verändern/vergrößen kann. |
||
|
|
Midimaster |
Antworten mit Zitat |
|---|---|---|
|
ja, ich brauch das oft für meine Spiele.
z.b. so: BlitzMax: [AUSKLAPPEN] Local tE:TTileEngine = New TTileEngine |
||
| Gewinner des BCC #53 mit "Gitarrist vs Fussballer" http://www.midimaster.de/downl...ssball.exe | ||

|
Thunder |
Antworten mit Zitat |
|---|---|---|
|
Schrolli hat Folgendes geschrieben: Kann ich in der Liste auf einzelne Elemente eigentlich irgendwie per ID zugreifen, ähnlich wie bei nem Array?
Oder gibt es einen anderen Datentyp der so etwas gut beherrscht? Brauche im Prinzip etwas, wie ein Array, dessen Größe ich aber variabel zur Laufzeit verändern/vergrößen kann. Listen sind sehr sehr schlecht in Zugriffen per Index. Die Performance wird sofort wegbrechen, weil dein Programm anfängt wild irgendwelche Adressen aus dem Speicher zu laden. Wenn du hauptsächlich Elemente hinzufügst und sie immer nur auf einmal löscht, dann verwende ein Array. Beispiel: BlitzMax: [AUSKLAPPEN] Type TTileLayer Siehe auch Slicing in der BlitzMax Doku. Die letzte operation verwendet Slices. Das bedeutet, dass man einen Teil des Arrays kopiert ( array[..2] ist eine Kopie von array, wo nur die ersten beiden Elemente enthalten sind). |
||
| Meine Sachen: https://bitbucket.org/chtisgit https://github.com/chtisgit | ||
|
|
Midimaster |
Antworten mit Zitat |
|---|---|---|
|
Wobei das mit dem "Performance-Einbruch relativ ist. Wenn Du einen Type mit 100 Layern hättest und darin ein Element auf die von mir beschriebene Index-Suche suchst, dann dauert das durchschnittlich 0.009 msec. Das heißt, selbst wenn so ein Suche 100x innerhalb eines FLIPs vorkommt verlierst du nur insgesamt 1msec von deinen 16 zur Verfügung stehenden. Meist liegt der Performance Ärger wo anders, (z.b. bei der zu erstellenden Grafik)
BlitzMax: [AUSKLAPPEN] Global SuchName$, Zeit# |
||
| Gewinner des BCC #53 mit "Gitarrist vs Fussballer" http://www.midimaster.de/downl...ssball.exe | ||
CO2ehemals "SirMO" |
Antworten mit Zitat |
|
|---|---|---|
|
Was sich bei sowas auch anbietet wäre eine Map. Eine Map ist eine Sammlung von Key-Value-Paaren. Der Vorteil von Maps ist, dass sie sehr schnell sind (nicht so schnell wie Arrays, aber schneller als Listen durchsuchen), da sie die enthaltenen Key-Value-Paare hashen (Frag' mich nicht, wie das genau funktioniert, ich weiß nur, dass es dadurch schneller wird, nach einem Key zu suchen Folgendes simples Beispiel eines Association-Types BlitzMax: [AUSKLAPPEN] Type TAssoc Dies wäre ein allgemeiner Association-Type, den du natürlich noch anpassen kannst, indem du in der Methode Add() kein Object, sondern deinen Datentyp erwartest; Selbiges gilt für Get(), bei der du kein Object, sondern deinen Datentyp zurückgibst (du musst dabei jedoch den Return von MapValueForKey() in den Ziel-Datentyp casten). In deinem Beispiel würde der obige Type die Liste ersetzen, deine Layer fügst du dann über TAssoc.Add() hinzu und rufst sie via TAssoc.Get() wieder ab. P.S.: Durchiterien durch die Map tust du mit MapValues() oder MapKeys(). |
||
|
mfG, CO²
Sprachen: BlitzMax, C, C++, C#, Java Hardware: Windows 7 Ultimate 64-Bit, AMX FX-6350 (6x3,9 GHz), 32 GB RAM, Nvidia GeForce GTX 750 Ti |
||
|
|
Thunder |
Antworten mit Zitat |
|---|---|---|
|
Okay, jetzt wird da schon viel durcheinander geschmissen (Schrolli hat ja nicht ganz genau gesagt was er möchte).
Wenn du einen Container möchtest, bei dem du die Elemente mit Index ansprechen kannst, wobei der Index von 0 bis (Anzahl der Elemente minus 1) geht -> das ist ein Array. Wenn du einen Container möchtest, bei dem du einen Key hast, und über den auf die Elemente zugreifen willst (z.B. Elemente = Mitarbeiter-Klassen und Key = Nachname des Mitarbeiters) -> das ist eine Map oder auch Hashtable. Man kann eine Map durchaus auch verwenden, wenn der Key ein Int ist - das ist aber nur sinnvoll, wenn die Keys <> 0, 1, 2, 3 ... sind. Denn dann sind wir wieder beim Array. Eine Map ist übrigens normalerweise ein Array aus LinkedLists (BlitzMax' TMap scheint aber auf den ersten Blick irgendwas mit Rot-Schwarz-Bäumen zu machen - dafuq? weiß jemand was genaueres?) Problem von BlitzMax-Map: Key muss ein Object sein, d.h. du kannst Int nur als Key verwenden, wenn du dir eine Dummy-Klasse baust, die ein Int-Field hat. Last and least, die Linked List. Sie punktet in der Theorie mit schnellem Einfügen und Entfernen. Vollständig über eine Linked List zu iterieren ist auch (in der Theorie) genau so effizient wie bei einem Array. Caches und langsame Hauptspeicher machen diese schöne Theorie aber kaputt und wenn du genügend viele Elemente hast (aber nicht zu viele), wird das Array schneller als die Linked List (in allen Belangen!). Das habe ich gerade mit BlitzMax gebenchmarkt. Wenn du wirklich wirklich viele Elemente hast (100e Millionen, Milliarden), dreht sich das wieder um (so weit geht mein Graph nicht). Ich hab mal geordnetes Einfügen von zufälligen Zahlen in Linked List bzw Array geplottet: 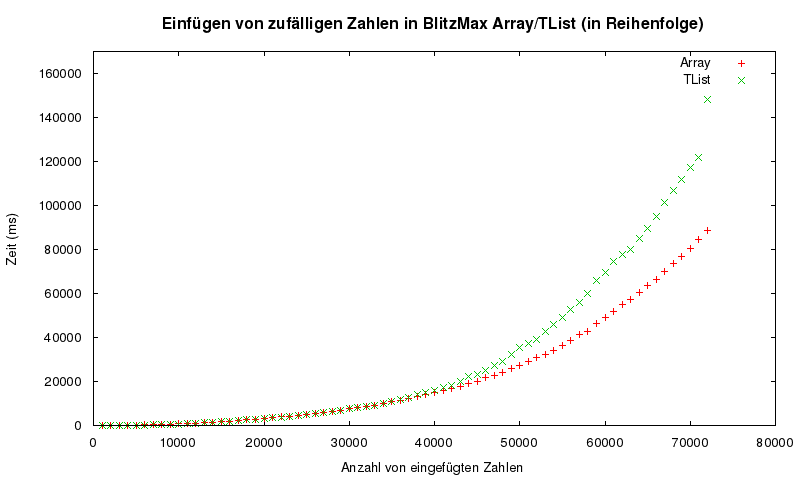
Das Problem ist: Index basierter Zugriff auf eine Linked List ist verdammt langsam und zwar immer (wirkt sich aber auch erst mit vielen Elementen aus (weswegen Midimasters 0.009 ms noch ganz harmlos klingen). Ein Plot (zufälliger zugriff auf Elemente einer Liste/eines Arrays): 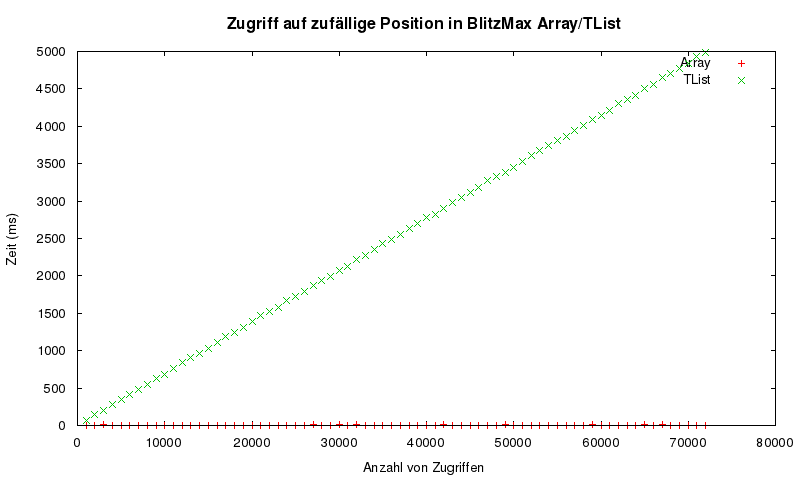
BlitzMax bräuchte von Haus aus eine ArrayList klasse (ähnlich Java), die das Managen von Arrays einfacher macht. Errata: BlitzMax: [AUSKLAPPEN] ' Ich habe im vorherigen Beitrag behauptet man dürfe folgendes: PS: Implementierung des Benchmarks: BlitzMax: [AUSKLAPPEN] Strict |
||
| Meine Sachen: https://bitbucket.org/chtisgit https://github.com/chtisgit | ||

|
DAK |
Antworten mit Zitat |
|---|---|---|
|
Jup, das Ganze mal noch von der Theorie her:
Array Ein Speicherblock einer bestimmten Größe wird beim Erstellen vorreserviert. Der Block bleibt dabei immer gleich groß, vergrößern oder verkleinern geht nicht. Will man sowas tun, dann muss ein neuer Block in der neuen Größe reserviert werden, und alles vom alten Array in das neue Array kopiert werden. Dadurch, das der Speicher aber eine fixe, vorherbestimmte Größe hat, kann man auf einzelne Objekte direkt zugreifen (indizieren), ohne Performance-Verlust, egal wie groß das Array ist. Also: -Größe von Anfang reserviert -Größe ändern kostet viel ( O(n) = Zeit abhängig von der Größe des Arrays) -Direkter Zugriff auf einzelne Objekte ist irre schnell ( O(1) = konstante Zugriffszeit, egal wie groß das Array ist) -Somit ist auch iterieren (die Elemente der Reihe nach durchgehen) gleich flott ( O(1) ) Linked List Hierbei wird für jedes Element der benötigte Speicherbereich neu reserviert. Jedes Element hat dabei einen Verweis (Link) auf das nächste (und je nach Implementierung auch das vorige) Element in der Liste. Dadurch ist neue Elemente hinzufügen oder Elemente löschen sehr schnell. Die Elemente iterieren ist auch sehr schnell, da jedes Element einen Link auf das nächste Element besitzt. Objekte indizieren ist aber sehr langsam, da man sich durch die ganze Liste Element für Element durchhanteln muss, um an den richtigen Punkt zu kommen. Also: -Größe dynamisch -Größe ändern ist billig ( O(1) ) -Indizieren braucht sehr lange ( O(n) = Zugriffszeit abhängig von der Anzahl der Elemente in der Liste) -Iterieren geht aber flott ( O(1) ) Array List Die Array List ist in BMax nicht von haus aus drinnen, ist aber sehr leicht zu implementieren. Diese ist im Grunde ein Array, das aber größer als benötigt initialisiert wird. Z.B. initialisiert man das Array mit 32 Plätzen, die am Anfang auf Null gesetzt sind. Dazu hat die Array List einen Zähler, wie voll sie ist. Wenn man ein Element hinzufügt, dann kommt es einfach an das erste freie Feld und der Zähler geht um eins hoch. Ist das Array voll, dann wird es, wie unter Array beschrieben auf die doppelte Größe erhöht und das Spiel geht weiter. Wird ein Element gelöscht, dann müssen alle nachfolgenden Elemente zurückverschoben werden, das kostet also. Dafür ist indizieren wieder so schnell wie bei Array. Also: -Größe halbdynamisch, mehr Speicherverbrauch als bei den Anderen -Elemente hinzufügen ist billig ( O(1) ) außer beim Resizen ( O(n) ), das aber selten vorkommt -Löschen ist eher teuer ( O(n) ) -Indizieren und iterieren geht sehr flott ( O(1) ) Map Ich gehe hier mal von HashMaps aus, da das die üblichste Implementierung ist. Hashmaps sind dazu da, das man schnell von einem Objekt auf ein anderes kommt, z.B. vom Namen eines Spielers zum Objekt, das dessen Raumschiff repräsentiert. Von der Datenspeicherung her, besteht eine HashMap aus einem Array mit Listen drinnen. Jede dieser Listen nennt man Buckets. Wird ein Objekt hinzugefügt, dann wird aus dem Objekt ein Hash erstellt (Hash=Identifikationszahl, die aus dem Objekt mathematisch errechnet wird). Dieser Hash bestimmt, in welchen Bucket das Objekt kommt. In diesem Bucket werden alle Objekte mit dem gleichen Hash gespeichert. Beim Auslesen wird das gleiche gemacht, und dann der Bucket nach dem Objekt mit dem gleichen Key gesucht. Das heißt, hier variieren die Zugriffszeiten, sind aber üblicherweise schneller als eine LinkedList, aber langsamer als ein Array oder eine ArrayList. Dafür können beliebige Werte als Key verwendet werden, nicht nur fortlaufende Zahlen. Also: -Größe dynamisch, aber da die Keys mitgespeichert werden müssen, schon eher groß -Elemente hinzufügen, löschen und indizieren ist generell eher billig ( O(1) ), kann aber im Extremfall auch etwas langsamer sein ( O(n) ) -Iterieren geht eigentlich nicht. Dafür muss man sich z.B. eine Liste aller Keys machen, und die iterieren und jeweils den Wert aus der Map raussuchen. -Im Gegensatz zu den anderen Strukturen gibt es in der HashMap auch eine Reihenfolge der Werte. Eine Map sortieren geht z.B. nicht. |
||
| Gewinner der 6. und der 68. BlitzCodeCompo | ||
Übersicht
Powered by phpBB © 2001 - 2006, phpBB Group